変分量子固有値ソルバー(VQE)
このレッスンでは、変分量子固有値ソルバー(Variational Quantum Eigensolver、VQE)を紹介し、量子コンピューティングにおける基礎的なアルゴリズムとしての重要性を説明するとともに、その強みと弱みも探っていきます。VQE単体では、補助的な手法なしに現代のユーティリティスケールな量子計算に対応するには不十分な可能性があります。しかしながら、古典-量子ハイブリッド手法の原型として重要であり、より高度なアルゴリズムの多くの基盤となっています。
このビデオは、VQEとその効率性に影響する要因の概要を示しています。以下のテキストでは、さらに詳しい説明と、Qiskitを使ったVQEの実装を行います。
1. VQEとは何か?
変分量子固有値ソルバーは、古典コンピューティングと量子コンピューティングを組み合わせてタスクを達成するアルゴリズムです。VQE計算には主に四つの構成要素があります。
- 演算子:最適化したいシステムの特性を記述するハミルトニアン( と呼びます)であることが多いです。言い換えると、この演算子の最小固有値に対応する固有ベクトルを求めることです。その固有ベクトルを「基底状態」と呼びます。
- 「アンザッツ(ansatz)」(ドイツ語で「アプローチ」を意味する言葉):これは、求めている固有ベクトルを近似する量子状態を準備する量子回路です。アンザッツはある種の量子回路の族(ファミリー)であり、回路内のいくつかのゲートはパラメータ化されています。つまり、変化させることができるパラメータが与えられています。この量子回路の族によって、基底状態を近似する量子状態の族を準備することができます。
- Estimator:現在の変分量子状態における演算子 の期待値を推定する手段です。求めたいものがこの期待値(コスト関数と呼びます)だけの場合もあります。また、1つ以上の期待値から始まるより複雑な関数が必要な場合もあります。
- 古典的オプティマイザ(最適化器):コスト関数を最小化しようとしてパラメータを変化させるアルゴリズムです。
それぞれの構成要素についてさらに詳しく見ていきましょう。
1.1 演算子(ハミルトニアン)
VQE問題の中心には、対象とするシステムを記述する演算子があります。ここでは、この演算子の最小固有値と対応する固有ベクトルが、何らかの科学的または業務上の目的に有用であると仮定します。例えば、分子を記述する化学ハミルトニアンでは、演算子の最小固有値が分子の基底状態エネルギーに対応し、対応する固有状態が分子の形状や電子配置を表します。あるいは演算子が最適化すべき特定のプロセスのコストを記述し、固有状態がルートや手順に対応する場合もあります。物理学などの分野では「ハミルトニアン」はほぼ常に物理系のエネルギーを記述する演算子を指します。しかし量子コンピューティングでは、ビジネスや物流の問題を記述する量子演算子も「ハミルトニアン」と呼ぶことが一般的です。ここではその慣例に従います。

物理的または最適化問題を量子ビットにマッピングすることは一般的に非自明なタスクですが、その詳細はこのコースの焦点ではありません。問題を量子演算子にマッピングする一般的な議論は Quantum computing in practice で確認できます。化学問題を量子演算子にマッピングする詳細については Quantum Chemistry with VQE を参照してください。
このコースでは、ハミルトニアンの形式が既知であると仮定します。例えば、単純な水素分子のハミルトニアン(特定の活性空間の仮定のもと、Jordan-Wignerマッパーを使用)は次のようになります。
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy
from qiskit.quantum_info import SparsePauliOp
hamiltonian = SparsePauliOp(
[
"IIII",
"IIIZ",
"IZII",
"IIZI",
"ZIII",
"IZIZ",
"IIZZ",
"ZIIZ",
"IZZI",
"ZZII",
"ZIZI",
"YYYY",
"XXYY",
"YYXX",
"XXXX",
],
coeffs=[
-0.09820182 + 0.0j,
-0.1740751 + 0.0j,
-0.1740751 + 0.0j,
0.2242933 + 0.0j,
0.2242933 + 0.0j,
0.16891402 + 0.0j,
0.1210099 + 0.0j,
0.16631441 + 0.0j,
0.16631441 + 0.0j,
0.1210099 + 0.0j,
0.17504456 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
],
)
上記のハミルトニアンには、ZZII や YYYY のような項が含まれており、互いに非可換です。つまり ZZII を評価するには量子ビット3でパウリZ演算子を測定する必要があります(他の測定も含む)。一方 YYYY を評価するには同じ量子ビット3でパウリY演算子を測定する必要があります。同じ量子ビット上のY演算子とZ演算子の間には不確定性関係があるため、これらを同時に測定することはできません。この点については後で再び取り上げます。
上記のハミルトニアンは の行列演算子です。最小エネルギー固有値を求めるために演算子を対角化することは難しくありません。
import numpy as np
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues), "hartrees")
The ground state energy is -1.1459778447627311 hartrees
古典的な総当たり固有値ソルバーでは、医薬品やタンパク質のような非常に大きな原子系のエネルギーや幾何学的構造を記述するためにスケールすることができません。VQEは、この問題に量子コンピューティングを活用しようとする初期の取り組みの1つです。
このレッスンでは上記よりはるかに大きなハミルトニアンを扱いますが、このコースの後半でVQEを補完・代替するより高度なツールを紹介する前に、VQEの限界を無理に押し広げることは避けたいと思います。
1.2 アンザッツ
「ansatz(アンザッツ)」はドイツ語で「アプローチ」を意味します。ドイツ語の正式な複数形は「ansätze」ですが、「ansatzes」や「ansatze」とも表記されることがあります。VQEの文脈では、アンザッツは研究しているシステムの基底状態に最も近い多量子ビット波動関数を生成するために使う量子回路であり、演算子の最低期待値を生成するものです。この量子回路は変分パラメータ(変数のベクトル にまとめられることが多い)を含みます。

変分パラメータの初期値 を選択します。回路上でのアンザッツのユニタリ操作を と呼びます。IBM®量子コンピュータでは、デフォルトですべての量子ビットが 状態に初期化されます。回路を実行すると、量子ビットの状態は次のようになります。
(物理系の言語を使うと)最低エネルギーだけが必要であれば、エネルギーを何度も測定して最小値を取ることで推定できます。しかし通常は、最低エネルギーまたは固有値をもたらす配置も知りたいと思います。次のステップはハミルトニアンの期待値の推定であり、これは量子測定によって達成されます。このプロセスを定性的に理解するには、エネルギー を測定する確率 が期待値と関係していることに注目します。
確率 は、固有状態 と現在のシステム状態 の重なりにも関係しています。
したがって、ハミルトニアンを構成するパウリ演算子を多数測定することで、現在のシステム状態 におけるハミルトニアンの期待値を推定できます。次のステップは、パラメータ を変化させて、システムの最低エネルギー(基底)状態により近づくことです。アンザッツに変分パラメータが含まれているため、これは 変分形式(variational form) とも呼ばれることがあります。
変分プロセスの前に、「良い推測」状態から始めることが有用な場合が多いことに注目してください。システムについて十分な知識があれば、 よりも良い初期推測を行うことができます。例えば、化学応用ではハートリー-フォック状態に量子ビットを初期化することが一般的です。変分パラメータを含まないこの初期推測を 参照状態(reference state) と呼びます。参照状態を生成するために使う量子回路を とします。参照状態とアンザッツの残りの部分を区別する必要がある場合は、 を使います。同等の表現として
1.3 エスティメータ
特定の変分状態 におけるハミルトニアンの期待値を推定する方法が必要です。演算子 全体を直接測定できれば、多数( 回とします)の測定値を平均するだけで済みます。
ここで 記号は、この期待値が の極限でのみ正確であることを示しています。回路上で何千もの測定が行われれば、期待値のサンプリング誤差は比較的低くなります。ただし、非常に精密な計算ではノイズなどの考慮事項が問題になります。
しかし一般的に、 を一度に測定することはできません。 は互いに非可換なパウリX、Y、Z演算子を複数含む場合があります。そのためハミルトニアンは、同時測定可能な演算子のグループに分解し、各グループを個別に推定してから結果を合算して期待値を得る必要があります。これについては次のレッスンで、古典的・量子的アプローチのスケーリングについて議論する際にさらに詳しく取り上げます。この測定の複雑さが、そのような推定を効率的に実行するための高度なコードが必要な理由の一つです。このレッスン以降では、この目的のためにQiskit Runtimeプリミティブ Estimator を使用します。
1.4 古典的オプティマイザ
古典的オプティマイザは、目的関数の極値(通常は最小値)を見つけるように設計された任意の古典的アルゴリズムです。可能なパラメータの空間を検索して、対象の関数を最小化するセットを見つけます。大まかに分類すると、勾配情報を利用する勾配法と、ブラックボックスとして動作する勾配なし法に分けられます。古典的オプティマイザの選択は、特に量子ハードウェアのノイズが存在する場合に、アルゴリズムの性能に大きく影響します。この分野でよく使われるオプティマイザにはAdam、AMSGrad、SPSAがあり、ノイズ環境で有望な結果を示しています。より伝統的なオプティマイザにはCOBYLAやSLSQPがあります。
一般的なワークフロー(セクション3.3で実演)は、これらのアルゴリズムの一つをscipyの minimize 関数などのミニマイザ内のメソッドとして使用することです。引数として以下のものを取ります。
- 最小化する関数。多くの場合、エネルギー期待値です。ただし一般的には「コスト関数」と呼ばれます。
- 検索を始めるパラメータのセット。多くの場合 または と呼ばれます。
- コスト関数の引数を含む引数群。QiskitによるQCでは、アンザッツ、ハミルトニアン、次のサブセクションで詳しく説明するEstimatorプリミティブが引数に含まれます。
- 最小化の「メソッド」。パラメータ空間を検索するために使用する具体的なアルゴリズムを指します。ここでCOBYLAやSLSQPなどを指定します。
- オプション。使用可能なオプションはメソッドによって異なりますが、ほぼすべてのメソッドに含まれる例として、検索を終了するまでのオプティマイザの最大反復回数
maxiterがあります。

各反復ステップで、ハミルトニアンの期待値が多数の測定によって推定されます。この推定エネルギーはコスト関数によって返され、ミニマイザはエネルギーランドスケープについての情報を更新します。次のステップを選ぶためにオプティマイザが行う動作はメソッドによって異なります。勾配を使用して最急降下方向を選ぶものもあります。ノイズを考慮して、その方向に真のエネルギーが減少すると判断する前に、コストが大幅に減少することを要求するものもあります。
# Example syntax for minimization
# from scipy.optimize import minimize
# res = minimize(cost_func, x0, args=(ansatz, hamiltonian, estimator), method="cobyla",
# options={'maxiter': 200})
1.5 変分原理
この文脈では変分原理が非常に重要です。変分原理は、どのような変分波動関数も基底状態波動関数が与えるエネルギー(またはコスト)期待値より低い期待値を与えることはできないと述べています。数学的に表すと、
これは、 のすべての固有状態の集合 がヒルベルト空間の完全基底を形成することに注目すると簡単に確認できます。言い換えると、任意の状態、特に を、 のこれらの固有状態の重み付き(規格化された)和として書くことができます。
ここで は決定すべき定数であり、 です。証明は読者への演習として残します。ただし、その意味に注目してください。最低エネルギー期待値を生成する変分状態こそが、真の基底状態の最良の推定です。
理解度チェック
任意の変分状態 に対して を数学的に確認してください。
Answer
エネルギー固有状態によって変分状態を展開した
を使うと、変分エネルギー期待値は次のように書けます。
すべての係数について が成り立ちます。したがって、
と書けます。
2. 古典的ワークフローとの比較
N行N列の行列に興味があるとします。行列が非常に大きく、完全な対角化が選択肢にない場合を考えます。さらに、問題について目標固有状態の全体的な構造についていくつかの推測ができるほど十分な知識があり、初期推測に似た状態を探索してコスト・エネルギーをさらに下げられるかを調べたいとします。これが変分アプローチであり、完全対角化が選択肢でない場合に使われる方法の一つです。
2.1 古典的ワークフロー
古典コンピュータを使用する場合、次のように動作します。
- 変化させるパラメータ を持つ推測状態を作ります:。この初期推測はランダムでも構いませんが、それは得策ではありません。手元の問題についての知識を使い、できる限り推測を絞り込みたいところです。
- その状態における演算子の期待値を計算します:
- 変分パラメータを変更して繰り返します:
- 変分部分空間の可能な状態のランドスケープについて蓄積された情報を使い、より良い推測を行い、目標状態に近づきます。変分原理によって、変分状態は目標基底状態の固有値より低い固有値を与えることができないことが保証されています。したがって、期待値が低いほど基底状態の近似が良くなります。
このアプローチの各ステップの難しさを考察してみましょう。パラメータの設定や更新は計算上容易です。難しいのは、有用で物理的に動機付けられた初期パラメータの選択です。以前の反復から蓄積された情報を使って基底状態に近づくようにパラメータを更新することは非自明です。しかし、これを非常に効率的に行う古典的最適化アルゴリズムが存在します。この古典的最適化は、多くの反復が必要になる可能性があるために高コストなだけです。最悪の場合、反復回数はNに対して指数関数的にスケールする可能性があります。最も計算コストの高いステップは、特定の状態 を使って行列の期待値を計算することでしょう:。
行列は 要素のベクトルに作用する必要があり、最悪の場合 の乗算操作に対応します。これをパラメータの各反復で行う必要があります。非常に大きな行列では、これは高い計算コストとなります。
2.2 量子ワークフローと可換パウリ群
次に、この計算部分を量子コンピュータに委ねることを考えてみましょう。期待値を計算する代わりに、変分アンザッツを使って量子コンピュータ上で状態 を準備し、測定を行うことで推定します。
これは言うほど簡単ではありません。 は一般的に測定が容易ではありません。例えば、互いに非可換な複数のパウリX、Y、Z演算子から構成される場合があります。しかし、 は測定可能な(例えばパウリ演算子や量子ビットごとに可換なパウリ演算子のグループなど)項 の線形結合として書くことができます。ある状態 における の期待値は、構成する項 の期待値の重み付き和です。この表現は任意の状態 に成り立ちますが、特に変分状態 に使います。
ここで は IZZX…XIYX のようなパウリ文字列か、互いに可換な複数のパウリ文字列です。したがって、量子コンピュータ上での測定の現実により近い期待値の説明は、
変分波動関数の文脈では、
各項 は 回測定され、測定サンプル ()を生成し、期待値 と標準偏差 を返します。これらの項を合算して誤差を伝播させることで、全体の期待値 と標準偏差 が得られます。
これは大規模な乗算も にスケールするプロセスも必要としません。代わりに量子コンピュータ上での複数の測定が必要です。それほど多くの測定が必要でなければ、このアプローチは効率的です。これがVQEの量子的な部分です。
しかし、これが効率的でない理由についても話しておきましょう。測定回数が多くなる理由の一つは、非常に高精度な計算のために推定の統計的不確実性を低減することです。もう一つの理由は、行列全体を表現するために必要なパウリ文字列の数です。パウリ行列(恒等行列を含む:X、Y、Z、I)は、与えられた次元のすべての演算子の空間を張るため、対象とする行列を以前のようにパウリ演算子の重み付き和として書けることが保証されています。
ここで は IZZX…XIYX のようなシステムを記述するすべての量子ビットに作用するパウリ文字列か、互いに可換な複数のパウリ文字列です。Qiskitはリトルエンディアン表記を使用しており、右から 番目のパウリ演算子が 番目の量子ビットに作用することを覚えておいてください。したがって、一連のパウリ演算子を測定することで演算子を測定できます。
しかし、これらのパウリ演算子をすべて同時に測定することはできません。同じ量子ビットに関連付けられた(Iを除く)パウリ演算子は互いに可換ではありません。例えば IZIZ と ZZXZ は同時に測定できます。3番目の量子ビットのIとZを同時に測定でき、1番目の量子ビットのIとXも同時に知ることができるからです。しかし ZZZZ と ZZZX は同時に測定できません。ZとXは可換でなく、どちらも0番目の量子ビットに作用するからです。経験豊富な読者は、各量子ビットの測定が個別には可換でなくても、2つのパウリ演算子グループがセットとして可換になる場合があることをご存じかもしれません。Estimator はテンソル積パウリ測定(基底回転による)を仮定しており、これは量子ビットごとに可換な演算子のグループ化に対応します。そのため、Estimator を使って2つのパウリ演算子文字列(AとB)を同時に推定するには、AとBの各量子ビットのパウリ演算子が可換でなければなりません。つまり ZZZZ と ZZXX も同時に測定できません。

したがって、行列 を異なる量子ビットに作用するパウリの和に分解します。その和のいくつかの要素は同時に測定できます。これを可換パウリ群と呼びます。非可換な項がいくつあるかによって、多くの群が必要になる場合があります。可換パウリ文字列のグループ数を とします。 が小さければうまく機能します。 に数百万のグループがある場合は、有用ではありません。
期待値推定に必要なプロセスは、Qiskit Runtimeプリミティブ Estimator にまとめられています。Estimatorの詳細については、IBM Quantum® DocumentationのAPIリファレンスを参照してください。Estimatorを直接使用することもできますが、Estimatorは最低エネルギー固有値だけでなく、アンサンブル標準誤差などの情報も返します。したがって、最小化問題の文脈では、コスト関数の中にEstimatorを使うことがよくあります。Estimatorの入力と出力の詳細については、IBM Quantum Documentationのこちらのガイドを参照してください。
パラメータ のセットに対する期待値(またはコスト関数)を記録し、パラメータを更新します。時間をかけて、アンザッツでサンプリングされた状態の部分空間でのコスト関数の勾配を近似するために、推定された期待値またはコスト関数値を使用することができます。勾配法と勾配なし法の両方が存在します。どちらも、複数の局所最小値や、ゼロに近い勾配を持つ大きなパラメータ空間領域(バレンプラトーと呼ばれる)などのトレーニング可能性の問題に悩まされる可能性があります。

2.3 計算コストを決める要因
VQEは最も困難な量子化学の問題すべてを解決するわけではありません。しかしそれが目的ではありません。計算コストを決める要因をシフトしたのです。

行列の次元だけに依存するプロセスから、必要な精度と行列を構成する非可換パウリ演算子の数に依存するプロセスへとシフトしました。後者は古典コンピューティングには対応するものがありません。
これらの依存関係に基づくと、疎な行列、または少数の非可換パウリ文字列を含む行列の場合に有用です。これは例えば、スピンが相互作用する系が該当します。密な行列の場合は有用性が低い可能性があります。例えば化学系では、数百、数千、さらには数百万のパウリ文字列を含むハミルトニアンを持つことがよく知られています。この項の数を減らすための興味深い研究が行われていますが、化学系はこのコースで説明する他のアルゴリズムの方が適している可能性があります。
理解度チェック
4量子ビットのハミルトニアンに、次の項が含まれているとします:
IIXX, IIXZ, IIZZ, IZXZ, IXXZ, ZZXZ, XZXZ, ZIXZ, ZZZZ, XXXX
これらの項を、同じグループ内のすべての項が同時に測定できるようにグループ分けしたいとします。すべての項を含めるために必要な最小のグループ数はいくつでしょうか?
Answer
4つのグループで可能です。なお、このような解は一般に一意ではありません。
IIXX, XXXX, IIZZ, ZZZZ
IIXZ, IZXZ, ZIXZ, ZZXZ
IXXZ
XZXZ
VQEによる量子化学計算を難しくする主な要因として、どちらが一般的だと思いますか:ハミルトニアンの項数、それとも良いアンザッツを見つけること?
Answer
化学的な文脈に高度に最適化されたアンザッツが存在することが分かっています。より多くの問題を引き起こすのは、ハミルトニアンの項数、つまり必要な測定回数の多さです。
3. ハミルトニアンの例
このアルゴリズムを小さなハミルトニアン行列を使って実際に試してみましょう。各ステップで何が起きているかを確認します。Qiskitパターンズのフレームワークを使用します:
- ステップ 1:問題を量子回路と演算子にマッピングする
- ステップ 2:ターゲットハードウェア向けに最適化する
- ステップ 3:ターゲットハードウェアで実行する
- ステップ 4:結果を後処理する
3.1 ステップ 1:問題を量子回路と演算子にマッピングする
上記の化学的文脈から定義したものを使用します。まず、一般的なインポートから始めます。
# General imports
import numpy as np
# SciPy minimizer routine
from scipy.optimize import minimize
# Plotting functions
import matplotlib.pyplot as plt
ここでも、対象のハミルトニアンは既知であると仮定します。このコースで取り上げる他の手法がより大きな問題を効率的に解けるため、ここでは非常に小さなハミルトニアンを使用します。
from qiskit.quantum_info import SparsePauliOp
import numpy as np
hamiltonian = SparsePauliOp.from_list(
[("YZ", 0.3980), ("ZI", -0.3980), ("ZZ", -0.0113), ("XX", 0.1810)]
)
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues))
The ground state energy is -0.702930394459531
Qiskitには多数の既製アンザッツの選択肢があります。ここでは efficient_su2 を使用します。
# Pre-defined ansatz circuit and operator class for Hamiltonian
from qiskit.circuit.library import efficient_su2
# Note that it is more common to place initial 'h' gates outside the ansatz.
# Here we specifically wanted this layer structure.
ansatz = efficient_su2(
hamiltonian.num_qubits, su2_gates=["h", "rz", "y"], entanglement="circular", reps=1
)
num_params = ansatz.num_parameters
print("This circuit has ", num_params, "parameters")
ansatz.decompose().draw("mpl", style="iqp")
This circuit has 4 parameters
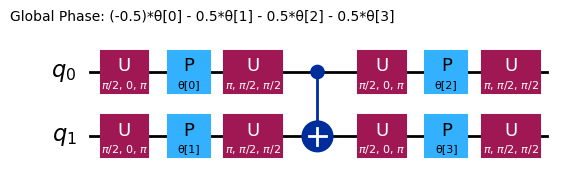
アンザッツが異なれば、エンタングリング構造も回転ゲートも異なります。ここで示したものはエンタングリングにCNOTゲートを使用し、回転にYゲートとパラメータ化されたRZゲートを使用しています。このパラメータ空間の大きさに注目してください。つまり、コスト関数を4つの変数(RZゲートのパラメータ)について最小化する必要があります。これはスケールアップできますが、無制限ではありません。4量子ビットの同様の問題を efficient_su2 のデフォルトの3 repsで実行すると、16個の変分パラメータが生じます。
3.2 ステップ 2:ターゲットハードウェア向けに最適化する
アンザッツは使い慣れたゲートで記述されていますが、各量子コンピューターで実装できる基底ゲートを使用するために、回路をトランスパイルする必要があります。最も空いているバックエンドを選択します。
# runtime imports
from qiskit_ibm_runtime import QiskitRuntimeService, Session
from qiskit_ibm_runtime import EstimatorV2 as Estimator
# To run on hardware, select the backend with the fewest number of jobs in the queue
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
print(backend)
<IBMBackend('ibm_torino')>
このハードウェア向けに回路をトランスパイルし、トランスパイルされたアンザッツを可視化できます。
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
ansatz_isa = pm.run(ansatz)
ansatz_isa.draw(output="mpl", idle_wires=False, style="iqp")

使用されているゲートが変わり、抽象回路の量子ビットが量子コンピューター上の異なる番号の量子ビットにマッピングされていることに注目してください。結果を意味のあるものにするために、ハミルトニアンも同じようにマッピングする必要があります。
hamiltonian_isa = hamiltonian.apply_layout(layout=ansatz_isa.layout)
3.3 ステップ 3:ターゲットハードウェアで実行する
3.3.1 値の出力
ここでは、前のステップで構築した構造(パラメータ、アンザッツ、ハミルトニアン)を引数として受け取るコスト関数を定義します。また、まだ定義していないEstimatorも使用します。収束の挙動を確認できるように、コスト関数の履歴を追跡するコードも含めます。
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from Estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (EstimatorV2): Estimator primitive instance
cost_history_dict: Dictionary for storing intermediate results
Returns:
float: Energy estimate
"""
pub = (ansatz, [hamiltonian], [params])
result = estimator.run(pubs=[pub]).result()
energy = result[0].data.evs[0]
cost_history_dict["iters"] += 1
cost_history_dict["prev_vector"] = params
cost_history_dict["cost_history"].append(energy)
print(f"Iters. done: {cost_history_dict['iters']} [Current cost: {energy}]")
return energy
cost_history_dict = {
"prev_vector": None,
"iters": 0,
"cost_history": [],
}
対象問題の知識やターゲット状態の特性に基づいて初期パラメータ値を選択できると非常に有利です。ここではそのような知識を仮定せず、ランダムな初期値を使用します。
x0 = 2 * np.pi * np.random.random(num_params)
# This required 13 min, 20 s QPU time on an Eagle processor, 28 min total time.
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
estimator.options.default_shots = 10000
res = minimize(
cost_func,
x0,
args=(ansatz_isa, hamiltonian_isa, estimator),
method="cobyla",
options={"maxiter": 50},
)
Iters. done: 1 [Current cost: 0.010575798722044727]
Iters. done: 2 [Current cost: 0.004040015974440895]
Iters. done: 3 [Current cost: 0.0020213258785942503]
Iters. done: 4 [Current cost: 0.18723082446726014]
Iters. done: 5 [Current cost: -0.2746792152068885]
Iters. done: 6 [Current cost: -0.3094547651648519]
Iters. done: 7 [Current cost: -0.05281985428356641]
Iters. done: 8 [Current cost: 0.00808560303514377]
Iters. done: 9 [Current cost: -0.0014821685303514388]
Iters. done: 10 [Current cost: -0.004759824281150161]
Iters. done: 11 [Current cost: 0.09942328705995292]
Iters. done: 12 [Current cost: 0.01092366214057508]
Iters. done: 13 [Current cost: 0.05017497496069776]
Iters. done: 14 [Current cost: 0.13028868414310696]
Iters. done: 15 [Current cost: 0.013747803514376994]
Iters. done: 16 [Current cost: 0.2583072432944498]
Iters. done: 17 [Current cost: -0.14422125655131562]
Iters. done: 18 [Current cost: -0.0004950150347678081]
Iters. done: 19 [Current cost: 0.00681082268370607]
Iters. done: 20 [Current cost: -0.0023377795527156544]
Iters. done: 21 [Current cost: 0.6027665591169237]
Iters. done: 22 [Current cost: 0.00596641373801917]
Iters. done: 23 [Current cost: -0.008318769968051117]
Iters. done: 24 [Current cost: -0.00026683306709265246]
Iters. done: 25 [Current cost: -0.007648222843450479]
Iters. done: 26 [Current cost: 0.004121086261980831]
Iters. done: 27 [Current cost: -0.004075019968051117]
Iters. done: 28 [Current cost: -0.004419369009584665]
Iters. done: 29 [Current cost: 0.213185460054037]
Iters. done: 30 [Current cost: -0.06505919572162797]
Iters. done: 31 [Current cost: -0.5334241316590271]
Iters. done: 32 [Current cost: 0.00218370607028754]
Iters. done: 33 [Current cost: 0.09579352143666908]
Iters. done: 34 [Current cost: -0.009274800319488819]
Iters. done: 35 [Current cost: -0.44395141360688106]
Iters. done: 36 [Current cost: 0.011747104632587858]
Iters. done: 37 [Current cost: -0.003344149361022364]
Iters. done: 38 [Current cost: 0.19138183916486304]
Iters. done: 39 [Current cost: 0.013513931813145209]
生の出力を確認できます。
res
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.5334241316590271
x: [ 1.024e+00 6.459e+00 3.625e+00 4.007e+00]
nfev: 39
maxcv: 0.0
3.4 ステップ 4:結果を後処理する
手続きが正しく終了した場合、辞書内の値はそれぞれ解ベクトルとコスト関数評価の総数と等しいはずです。これは簡単に確認できます:
cost_history_dict
{'prev_vector': array([1.02397956, 6.45886604, 3.62479262, 4.00744128]),
'iters': 39,
'cost_history': [np.float64(0.010575798722044727),
np.float64(0.004040015974440895),
np.float64(0.0020213258785942503),
np.float64(0.18723082446726014),
np.float64(-0.2746792152068885),
np.float64(-0.3094547651648519),
np.float64(-0.05281985428356641),
np.float64(0.00808560303514377),
np.float64(-0.0014821685303514388),
np.float64(-0.004759824281150161),
np.float64(0.09942328705995292),
np.float64(0.01092366214057508),
np.float64(0.05017497496069776),
np.float64(0.13028868414310696),
np.float64(0.013747803514376994),
np.float64(0.2583072432944498),
np.float64(-0.14422125655131562),
np.float64(-0.0004950150347678081),
np.float64(0.00681082268370607),
np.float64(-0.0023377795527156544),
np.float64(0.6027665591169237),
np.float64(0.00596641373801917),
np.float64(-0.008318769968051117),
np.float64(-0.00026683306709265246),
np.float64(-0.007648222843450479),
np.float64(0.004121086261980831),
np.float64(-0.004075019968051117),
np.float64(-0.004419369009584665),
np.float64(0.213185460054037),
np.float64(-0.06505919572162797),
np.float64(-0.5334241316590271),
np.float64(0.00218370607028754),
np.float64(0.09579352143666908),
np.float64(-0.009274800319488819),
np.float64(-0.44395141360688106),
np.float64(0.011747104632587858),
np.float64(-0.003344149361022364),
np.float64(0.19138183916486304),
np.float64(0.013513931813145209)]}
fig, ax = plt.subplots()
x = np.linspace(0, 10, 50)
# Define the constant function
constant = -0.7029
y_constant = np.full_like(x, constant)
ax.plot(
range(cost_history_dict["iters"]), cost_history_dict["cost_history"], label="VQE"
)
ax.set_xlabel("Iterations")
ax.set_ylabel("Cost")
ax.plot(y_constant, label="Target")
plt.legend()
plt.draw()

IBM Quantumでは、VQEに関連するその他のスキルアップ教材を提供しています。VQEを実際に試す準備ができている方は、チュートリアル「ハイゼンベルク鎖のVQEによる基底状態エネルギー推定」を参照してください。分子ハミルトニアンの作成についてより詳しく知りたい方は、「VQEによる量子化学」コースのこのレッスンを参照してください。VQEのような変分アルゴリズムの仕組みをより深く理解したい方には、「変分アルゴリズム設計」コースをお勧めします。
理解度チェック
このセクションでは、ハミルトニアンから基底状態エネルギーを計算しました。これを、例えば分子の構造決定に応用したい場合、どのように拡張すればよいでしょうか?
Answer
原子間距離や結合角に関する変数を導入し、それらを変化させる必要があります。それぞれの変化に対して新しいハミルトニアンを生成します(エネルギーを記述する演算子は当然ながら構造に依存するためです)。生成された各ハミルトニアンをキュービットにマッピングするたびに、上記と同様の最適化を実行する必要があります。収束した多数の最適化問題の中で、最も低いエネルギーをもたらす構造が自然界に採用されるものとなります。これは上記で示した内容よりもかなり複雑です。このような計算は、最も単純な分子である に対してこちらで実施されています。
4. VQEと他の手法との関係
このセクションでは、オリジナルのVQEアプローチの長所と短所を振り返り、より新しいアルゴリズムとの関係を示します。
4.1 VQEの強みと弱み
いくつかの強みはすでに指摘されています。それらには以下が含まれます:
- 現代のハードウェアへの適合性:一部の量子アルゴリズムは、大規模なフォールトトレランスに近い、はるかに低いエラー率を必要とします。VQEはそうではなく、現在の量子コンピューター上で実装可能です。
- 浅い回路:VQEは比較的浅い量子回路を用いることが多いです。これにより、VQEは累積ゲートエラーの影響を受けにくく、多くのエラー緩和技術に適しています。ただし、回路が常に浅いとは限りません。これは使用するアンザッツによって異なります。
- 汎用性:VQEは(原則として)固有値/固有ベクトル問題として定式化できる任意の問題に適用できます。ただし、VQEが非現実的または不利となる問題に対する多くの注意点があります。それらの一部を以下に要約します。
VQEの弱みと実用上の問題点も上記で説明されています。これらには以下が含まれます:
- ヒューリスティックな性質:VQEはアンザッツと最適化手法の選択に性能が依存するため、正しい基底状態エネルギーへの収束を保証しません[1-2]。所望の基底状態に必要なエンタングルメントを欠く不適切なアンザッツが選ばれると、どの古典最適化器もその基底状態に到達できません。
- 潜在的に多数のパラメーター:非常に表現力の高いアンザッツは、パラメーターが非常に多く、最小化の反復に非常に時間がかかる場合があります。
- 高い測定オーバーヘッド:VQEでは、Estimatorを使用してハミルトニアンの各項の期待値を推定します。対象となるほとんどのハミルトニアンには、同時に推定できない項があります。これにより、複雑なハミルトニアンを持つ大規模システムでは、VQEがリソース集約的になる可能性があります[1]。
- ノイズの影響:古典最適化器が最小値を探索する際、ノイズの多い計算がそれを混乱させ、真の最小値から遠ざけたり、収束を遅らせたりする可能性があります。この問題の対策として、IBMの最先端のエラー緩和・エラー抑制技術[2-3]を活用することが考えられます。
- バレンプラトー:これらの勾配消失領域[2-3]はノイズがない場合でも存在しますが、ノイズがあるとより厄介になります。なぜなら、ノイズによる期待値の変化が、これらのバレン領域でパラメーターを更新することによる変化よりも大きくなる可能性があるためです。
4.2 他のアプローチとの関係
Adapt-VQE
ADAPT-VQE(Adaptive Derivative-Assembled Pseudo-Trotter Variational Quantum Eigensolver)アルゴリズムは、オリジナルのVQEアルゴリズムを拡張したもので、特に量子化学における量子シミュレーションの効率性・精度・スケーラビリティを改善するために設計されています。
このレッスン全体で説明したオリジナルのVQEアルゴリズムは、事前に定義された固定アンザッツを使用してシステムの基底状態を近似します。今回の例では、efficient_su2 を1回の繰り返しでYゲートとRZ回転ゲートを使用しました。RZゲートのパラメーターは変化しましたが、アンザッツの構造と使用するゲートは変化しませんでした。
ADAPT-VQEは、適応的なアンザッツ構築によってVQEの制限に対処します。固定アンザッツから始める代わりに、ADAPT-VQEはアンザッツを反復的に動的に構築します。各ステップで、事前に定義されたプール(フェルミオン励起演算子など)の中からエネルギーに対して最大の勾配を持つ演算子を選択します。これにより、最も影響力のある演算子のみが追加され、コンパクトで効率的なアンザッツが得られます[4-6]。このアプローチはいくつかの有益な効果をもたらします:
- 回路深さの削減:アンザッツを段階的に成長させ、必要な演算子のみに焦点を当てることで、ADAPT-VQEは従来のVQEアプローチと比較してゲート操作を最小化します[5,7]。
- 精度の向上:適応的な性質により、ADAPT-VQEは各ステップでより多くの相関エネルギーを回復でき、従来のVQEが苦手とする強相関系に対して特に効果的です[8,9]。
- スケーラビリティとノイズ耐性:コンパクトなアンザッツにより、ゲートエラーの蓄積が抑制され、計算オーバーヘッドが軽減され、最小化する必要のある変分パラメーターの数が制限されます。
ADAPT-VQEはまだ完全ではありません。場合によっては局所最小値に捕捉されたり、速度が低下したりする可能性があり、過パラメーター化の問題も抱えることがあります。また、多くのゲート構造で勾配の計算とパラメーターの最適化が必要なため、かなりリソース集約的になることもあります。
量子位相推定(QPE)
QPEはVQEと目的が似ていますが、実装は大きく異なります。QPEは一般的に深い量子回路と高いコヒーレンスを必要とするため、フォールトトレラント量子コンピューターが必要です。QPEが実装できるようになれば、VQEよりも高精度になります。両者の違いを表す方法の一つは、回路深さの関数としての精度です。QPEは回路深さが のスケールで精度 を達成します[10]。VQEは同じ精度を達成するために 回のサンプリングが必要です[10,11]。
このコースのKrylov、SQD、QSCIなど
VQEは、量子コンピューターを操作するためだけでなく、アルゴリズムの実質的な部分においても古典コンピューターに依存する量子アルゴリズムの確立に貢献しました。このようなアルゴリズムのいくつかが、このコースの残りの部分の焦点です。ここでは、VQEと比較・対比するために、いくつかの概要を簡単に説明します。詳細は後続のレッスンで説明します。
クリロフ量子対角化(KQD)
__クリロフ部分空間法__は、行列を部分空間に射影して次元を削減し、最も重要な特徴を保持しながら扱いやすくする手法です。この手法のポイントの一つは、これらの特徴を保持する部分空間を生成することですが、この部分空間の生成は、量子コンピューター上の確立された手法である__トロッター化__と密接に関連しています。
量子クリロフ法にはいくつかのバリアントがありますが、一般的なアプローチは以下の通りです:
- 量子コンピューターを使用して、トロッター化によってサブスペース(クリロフ部分空間)を生成する
- 対象行列をそのクリロフ部分空間に射影する
- 古典コンピューターを使用して、新しく射影されたハミルトニアンを対角化する
サンプリングベース量子対角化(SQD)
__サンプリングベース量子対角化(SQD)__は、対角化する行列の次元を削減しながら主要な特徴を保持しようとするという点でクリロフ法に関連しています。SQDは以下の方法でこれを実現します:
- 基底状態の初期推定を行い、その基底状態にシステムを準備する。
- サンプラーを使用して、この状態を構成するビット列をサンプリングする。
- サンプラーから得られた計算基底状態の集合を、対象行列を射影する部分空間として使用する。
- 古典コンピューターを使用して、より小さな射影された行列を対角化する。
これは、アルゴリズムの実質的な部分において古典コンピューティングと量子コンピューティングを活用するという点でVQEに関連しています。また、どちらも試行状態またはアンザッツに対する良好な初期推定が必要という要件を共有しています。しかし、SQDにおける古典コンピューターと量子コンピューターの間の作業分担は、クリロフ法のそれに近いです。
実際に、クリロフ法とSQDは最近、サンプリングベースのクリロフ量子対角化(SKQD)法[12]に組み合わされています。
量子部分空間配置間相互作用
量子選択配置間相互作用(QSCI)[13]は、試行波動関数をサンプリングして重要な計算基底状態を特定し、古典的な対角化のための部分空間を生成することで、ハミルトニアンの近似基底状態を求めるアルゴリズムです。SQDとQSCIはどちらも、量子コンピューターを使用して縮小された部分空間を構築します。QSCIの追加の強みは、特に化学問題の文脈における状態準備にあります。時間発展状態[14]の使用や化学にインスパイアされたアンザッツのセットなど、さまざまな戦略を活用します。効率的な状態準備に焦点を当てることで、QSCIは量子状態サンプリング技術からのノイズ耐性を活用しながら、化学ハミルトニアンの量子計算コストを高い忠実度を保ちながら削減します[15]。QSCIはまた、より良い結果のためのより多くのアンザッツを提供する適応的構築技術も提供します。
化学問題に対するQSCIのデフォルトワークフローは以下の通りです:
- 選択したソフトウェア(SciPyなど)を使用して分子ハミルトニアンを構築する。
- 適切な初期状態と事前に選択されたパラメーターのセットを持つ化学にインスパイアされたアンザッツを選択して、QSCIアルゴリズムを準備する。
- 重要な基底状態をサンプリングし、古典コンピューターを使用してハミルトニアンを対角化して基底状態エネルギーを求める。
- 多くの場合、後処理技術として配置回復[16]と対称性後選択[15]を使用する。
- オプションとして、適応的QSCIのワークフローでは、ランダムな初期状態でより多くのアンザッツを使用することにより、ステップ2からステップ3への追加の最適化ループがある。
理解度チェック
上記に挙げたすべての手法(詳しく説明されていないQPEを除く)とVQEの共通点は何ですか?
Answer
すべての手法は何らかの試行状態または波動関数を含みます。また、この試行状態の初期推定が優れているほど、すべての手法がより良く機能します。
もう一つの正解は、ハミルトニアンが測定しやすい場合(比較的少数の可換パウリ演算子のグループに分類できる場合)に、すべての手法が最も実装しやすくなるということです。
上記に挙げた他のすべての手法とVQEの相違点は何ですか?
Answer
古典最適化器です。他の手法はいずれも変分パラメーターを選択するために古典最適化アルゴリズムを使用しません。
参考文献
[2] https://en.wikipedia.org/wiki/Variational_quantum_eigensolver
[3] https://journals.aps.org/prapplied/abstract/10.1103/PhysRevApplied.19.024047
[4] https://arxiv.org/abs/2111.05176
[6] https://inquanto.quantinuum.com/tutorials/InQ_tut_fe4n2_2.html
[7] https://www.nature.com/articles/s41467-019-10988-2
[8] https://arxiv.org/abs/2210.15438
[9] https://journals.aps.org/prresearch/abstract/10.1103/PhysRevResearch.6.013254
[10] https://arxiv.org/html/2403.09624v1
[11] https://www.nature.com/articles/s42005-023-01312-y
[13] https://arxiv.org/abs/1802.00171
[14] https://arxiv.org/abs/2103.08505
[15] https://arxiv.org/html/2501.09702v1
[16] https://quri-sdk.qunasys.com/docs/examples/quri-algo-vm/qsci/
[17] https://arxiv.org/abs/2412.13839