動的回路による長距離エンタングルメント
使用量の目安: Heron r2プロセッサで約4分。(注意: これはあくまで目安です。実際の実行時間は異なる場合があります。)
学習成果
このチュートリアルを完了すると、以下について学ぶことができます:
- 回路中間測定(MCM)と古典フィードフォワードを用いた動的回路で長距離CNOTゲートを実装する方法;
- 等価なゲートをユニタリSWAPベースのアプローチで実装する方法;
- 量子ビット間の距離の関数としてゲートフィデリティを測定することで、両アプローチを比較する方法。
前提条件
本チュートリアルを進める前に、以下のトピックに慣れておくことを推奨します:
- ベル状態、エンタングルメント、量子ゲートを含む基本的な量子計算の概念;
- 動的回路(回路中間測定と古典フィードフォワード)への慣れ;
- Qiskit SDK および Qiskit Runtime の基本的な知識と IBM Quantum® アカウント へのアクセス。
背景
限られた接続性を持つデバイス上で、離れた量子ビット間の長距離エンタングルメントを実現することは困難です。本チュートリアルでは、測定ベースのプロトコルを用いた長距離制御X(LRCX)ゲートの実装を通じて、動的回路がそのようなエンタングルメントをどのように生成できるかを示します。
Elisa Bäumer らによる 1 のアプローチに従い、この手法は回路中間測定とフィードフォワードを使用して、量子ビット間の距離に関係なく一定深度のゲートを実現します。中間ベルペアを生成し、各ペアから1つの量子ビットを測定し、古典的に条件付けされたゲートを適用して、デバイス全体にエンタングルメントを伝播させます。これにより、長いSWAPチェーンを回避し、回路深度と2量子ビットゲートエラーへの露出の両方を削減できます。
本ノートブックでは、IBM Quantum ハードウェア向けにプロトコルを適応させ、制御-ターゲット間の距離の関数として性能をベンチマークし、ユニタリSWAPベースのベースラインと比較します。
要件
本チュートリアルを開始する前に、以下がインストールされていることを確認してください:
- Qiskit SDK v2.0以降(visualization サポート付き)
- Qiskit Runtime v0.37以降(
pip install qiskit-ibm-runtime) - Qiskit Aer v0.17以降(
pip install qiskit-aer)
セットアップ
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-aer qiskit-ibm-runtime
from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister
from qiskit.circuit.classical import expr
from qiskit.transpiler import generate_preset_pass_manager
from qiskit.visualization import plot_circuit_layout
from qiskit_ibm_runtime import (
QiskitRuntimeService,
Batch,
SamplerV2 as Sampler,
)
import matplotlib.pyplot as plt
import numpy as np
小規模シミュレータの例
実際のQPUで実行する前に、動的回路とユニタリ回路の両方がノイズのないシミュレータ上で理想的なベル状態を生成することを確認します。Qiskit Runtimeの Sampler を AerSimulator をバックエンドモードとして使用し、距離6の小規模な例で実行します。
ステップ1: 古典的な入力を量子問題にマッピングする
次に、以下に示す動的回路の構成(参考文献 1 の図1aから改変)に従って、2つの離れた量子ビット間の長距離CNOTゲートを実装します。重要なアイデアは、 に初期化されたアンシラ量子ビットの「バス」を使用して、長距離ゲートテレポーテーションを仲介することです。
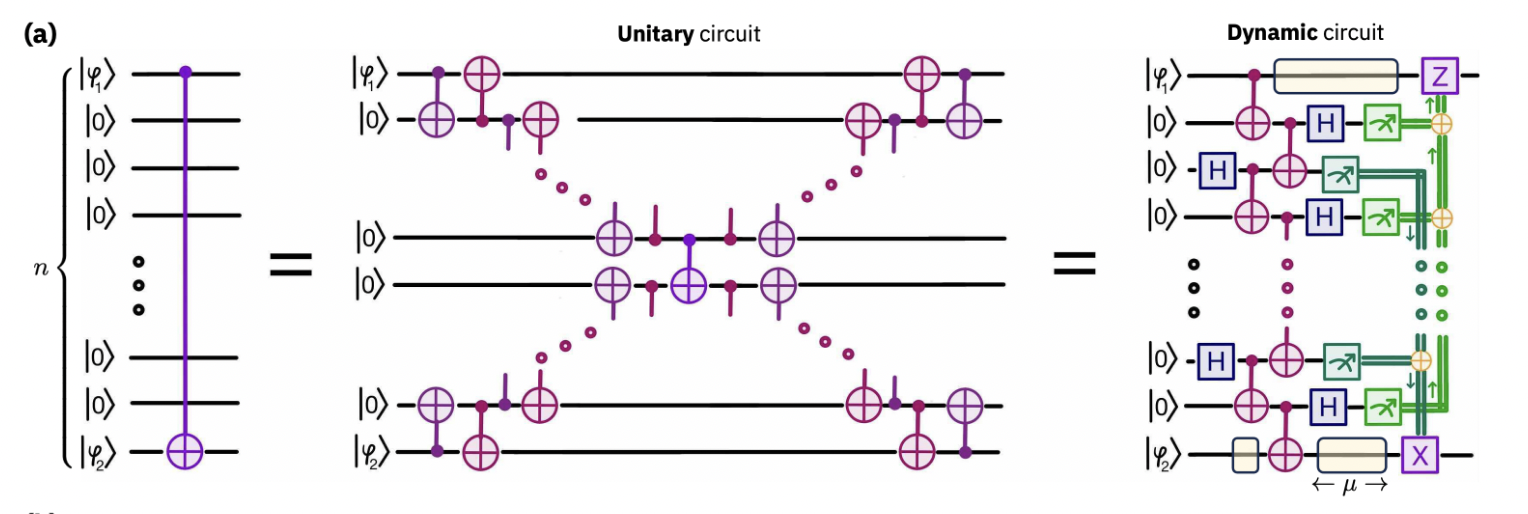
図に示されているように、プロセスは以下の通りです:
- 中間アンシラを介して制御量子ビットとターゲット量子ビットを接続するベルペアのチェーンを準備します。
- エンタングルされていない隣接量子ビット間でベル測定を実行し、制御ビットとターゲットビットがベルペアを共有するまで、エンタングルメントをステップごとにスワップします。
- このベルペアをゲートテレポーテーションに使用し、局所的なCNOTを一定深度で決定論的な長距離CNOTに変換します。
このアプローチは、長いSWAPチェーンを一定深度のプロトコルに置き換え、2量子ビットゲートエラーへの露出を減らし、デバイスサイズに対してスケーラブルな操作を実現します。
以下では、まずLRCX回路の動的回路による実装を順を追って説明します。最後に、動的回路の利点を強調するために、ユニタリベースの実装も比較用に提供します。
回路の初期化
比較の基礎となる簡単な量子問題から始めます。具体的には、インデックス0の制御量子ビットを持つ回路を初期化し、アダマールゲートを適用します。これにより重ね合わせ状態が生成され、制御X操作が続くことで、制御量子ビットとターゲット量子ビットの間にベル状態 が生成されます。
この段階では、まだ長距離制御X(LRCX)自体を構築していません。代わりに、LRCXの役割を明確にするための、明快で最小限の初期回路を定義することが目標です。ステップ2では、動的回路を用いた最適化としてLRCXをどのように実装できるかを示し、ユニタリ等価物との性能比較を行います。重要なのは、LRCXプロトコルはどのような初期回路にも適用可能であるということです。ここでは、デモンストレーションの明確さのために、この簡単なアダマールのセットアップを使用します。
distance = 6 # The distance of the CNOT gate, with the convention that a distance of zero is a nearest-neighbor CNOT.
def initialize_circuit(distance):
assert distance >= 0
control = 0 # control qubit
n = distance # number of qubits between target and control
qr = QuantumRegister(
n + 2, name="q"
) # Circuit with n qubits between control and target
cr = ClassicalRegister(
2, name="cr"
) # Classical register for measuring control and target qubits
k = int(n / 2) # Number of Bell States to be used
allcr = [cr]
if (
distance > 1
): # This classical register will be used to store ZZ measurements.
# It is only used for long-range CX gates with distance > 1
c1 = ClassicalRegister(
k, name="c1"
) # Classical register needed for post processing
allcr.append(c1)
if (
distance > 0
): # This classical register will be used to store XX measurements.
# It is only used if distance > 0
c2 = ClassicalRegister(
n - k, name="c2"
) # Classical register needed for post processing
allcr.append(c2)
qc = QuantumCircuit(qr, *allcr, name="CNOT")
# Apply a Hadamard gate to the control qubit such that the
# long-range CNOT gate will prepare a
# Bell state (|00> + |11>)/sqrt(2)
qc.h(control)
return qc
qc = initialize_circuit(distance)
qc.draw(fold=-1, output="mpl", scale=0.5)

ステップ2: 量子ハードウェア実行のための問題の最適化
このステップでは、動的回路を使用してLRCX回路を構築する方法を示します。目標は、純粋にユニタリな実装と比較して深度を削減することで、ハードウェア上での実行に向けて回路を最適化することです。利点を説明するために、動的LRCX構成とそのユニタリ等価物の両方を表示し、トランスパイル後の性能を比較します。重要なのは、ここではLRCXを簡単なアダマール初期化問題に適用していますが、このプロトコルは長距離CNOTが必要なあらゆる回路に適用可能であるということです。
ベルペアの準備
制御量子ビットとターゲット量子ビットの間のパスに沿って、ベルペアのチェーンを作成することから始めます。距離が奇数の場合は、まず制御ビットからその隣接ビットへのCNOTを適用します。これがテレポートされるCNOTです。偶数距離の場合、このCNOTはベルペア準備ステップの後に適用されます。次に、ベルペアチェーンが連続するペアの量子ビットをエンタングルし、制御情報をデバイス全体に伝搬するために必要なリソースを確立します。
# Determine where to start the Bell pair chain and add an extra CNOT when n is odd
def check_even(n: int) -> int:
"""Return 1 if n is even, else 2."""
return 1 if n % 2 == 0 else 2
def prepare_bell_pairs(qc, add_barriers=True):
n = qc.num_qubits - 2 # number of qubits between target and control
k = int(n / 2)
if add_barriers:
qc.barrier()
x0 = check_even(n)
if n % 2 != 0:
qc.cx(0, 1)
# Create k Bell pairs
for i in range(k):
qc.h(x0 + 2 * i)
qc.cx(x0 + 2 * i, x0 + 2 * i + 1)
return qc
qc = prepare_bell_pairs(qc)
qc.draw(output="mpl", fold=-1, scale=0.5)

隣接量子ビットペアをベル基底で測定する
次に、エンタングルされていない隣接量子ビットをベル基底( と の2量子ビット測定)で測定します。これにより、ターゲット量子ビットと制御ビットに隣接する量子ビットの間に長距離ベルペアが生成されます(パウリ補正が必要であり、次のステップでフィードフォワードにより実装されます)。並行して、CNOTゲートを目的のターゲット量子ビットにテレポートするエンタングル測定を実装します。
def measure_bell_basis(qc, add_barriers=True):
n = qc.num_qubits - 2 # number of qubits between target and control
k = int(n / 2)
if n > 1:
_, c1, c2 = qc.cregs
elif n > 0:
_, c2 = qc.cregs
# Determine where to start the Bell pair chain and add an extra CNOT
# when n is odd
x0 = 1 if n % 2 == 0 else 2
# Entangling layer that implements the Bell measurement
# (and additionally adds the CNOT to be
# teleported, if n is even)
for i in range(k + 1):
qc.cx(x0 - 1 + 2 * i, x0 + 2 * i)
for i in range(1, k + x0):
if i == 1:
qc.h(2 * i + 1 - x0)
else:
qc.h(2 * i + 1 - x0)
if add_barriers:
qc.barrier()
# Map the ZZ measurements onto classical register c1
for i in range(k):
if i == 0:
qc.measure(2 * i + x0, c1[i])
else:
qc.measure(2 * i + x0, c1[i])
# Map the XX measurements onto classical register c2
for i in range(1, k + x0):
if i == 1:
qc.measure(2 * i + 1 - x0, c2[i - 1])
else:
qc.measure(2 * i + 1 - x0, c2[i - 1])
return qc
qc = measure_bell_basis(qc)
qc.draw(output="mpl", fold=-1, scale=0.5)

パウリ副産物演算子を補正するためのフィードフォワード補正を適用する
ベル基底測定はパウリ副産物を導入するため、記録された測定結果を使用してこれらを補正する必要があります。これは2つのステップで行われます。まず、すべての 測定のパリティを計算し、その結果を使用して条件付きで ゲートをターゲット量子ビットに適用します。同様に、 測定のパリティを計算し、条件付きで ゲートを制御量子ビットに適用します。
Qiskitの新しい古典式フレームワークを使用すると、これらのパリティを回路の古典処理層で直接計算できます。個々の測定ビットごとに一連の条件付きゲートを適用する代わりに、すべての関連する測定結果のXOR(パリティ)を表す単一の古典式を構築できます。この式は単一の if_test ブロックの条件として使用され、補正ゲートを一定深度で適用できます。このアプローチは回路を簡素化するとともに、フィードフォワード補正が不要な追加レイテンシを導入しないことを保証します。
def apply_ffwd_corrections(qc):
control = 0 # control qubit
target = qc.num_qubits - 1 # target qubit
n = qc.num_qubits - 2 # number of qubits between target and control
k = int(n / 2)
x0 = check_even(n)
if n > 1:
_, c1, c2 = qc.cregs
elif n > 0:
_, c2 = qc.cregs
# First, let's compute the parity of all ZZ measurements
for i in range(k):
if i == 0:
parity_ZZ = expr.lift(
c1[i]
) # Store the value of the first ZZ measurement in parity_ZZ
else:
parity_ZZ = expr.bit_xor(
c1[i], parity_ZZ
) # Successively compute the parity via XOR operations
for i in range(1, k + x0):
if i == 1:
parity_XX = expr.lift(
c2[i - 1]
) # Store the value of the first XX measurement in parity_XX
else:
parity_XX = expr.bit_xor(
c2[i - 1], parity_XX
) # Successively compute the parity via XOR operations
if n > 0:
with qc.if_test(parity_XX):
qc.z(control)
if n > 1:
with qc.if_test(parity_ZZ):
qc.x(target)
return qc
qc = apply_ffwd_corrections(qc)
qc.draw(output="mpl", fold=-1, scale=0.5)

制御量子ビットとターゲット量子ビットを測定する
制御量子ビットとターゲット量子ビットを 、、または 基底で測定するためのヘルパー関数を定義します。ベル状態 を検証するには、 と の期待値がともに であるべきです。これらはこの状態のスタビライザだからです。 測定もここでサポートされており、以下でフィデリティを計算する際に使用されます。
def measure_in_basis(qc, basis="XX", add_barrier=True):
control = 0 # control qubit
target = qc.num_qubits - 1 # target qubit
assert basis in ["XX", "YY", "ZZ"]
qc = (
qc.copy()
) # We copy the circuit because we want to measure in different bases
cr = qc.cregs[0]
if add_barrier:
qc.barrier()
if basis == "XX":
qc.h(control)
qc.h(target)
elif basis == "YY":
qc.sdg(control)
qc.sdg(target)
qc.h(control)
qc.h(target)
qc.measure(control, cr[0])
qc.measure(target, cr[1])
return qc
qc_YY = measure_in_basis(qc.copy(), basis="YY")
qc_YY.draw(
output="mpl", fold=-1, scale=0.5
) # Circuit for measuring in the YY basis

すべてをまとめる
上記で定義した各ステップを組み合わせて、1次元(1D)の線上の両端に長距離CXゲートを作成します。ステップには以下が含まれます:
- 制御量子ビットを に初期化する
- ベルペアを準備する
- 隣接量子ビットペアを測定する
- MCMに依存するフィードフォワード補正を適用する
def lrcx(distance, prep_barrier=True, pre_measure_barrier=True):
qc = initialize_circuit(distance)
qc = prepare_bell_pairs(qc, prep_barrier)
qc = measure_bell_basis(qc, pre_measure_barrier)
qc = apply_ffwd_corrections(qc)
return qc
qc = lrcx(distance)
# Apply the measurement in the XX, YY, and ZZ bases
qc_XX, qc_YY, qc_ZZ = [
measure_in_basis(qc, basis=basis) for basis in ["XX", "YY", "ZZ"]
]
qc_YY.draw(
output="mpl", fold=-1, scale=0.5
) # Circuit for measuring in the YY basis
ユニタリベースの実装:量子ビットを中央にスワップする方法
比較のために、まず最近接接続とユニタリゲートを使用して長距離CNOTゲートを実装する場合を検討します。以下の図で、左側は最近接接続のみを持つn量子ビットの1Dチェーン上の長距離CNOTゲートの回路です。中央は回路深度 の局所CNOTゲートで実装可能な等価なユニタリ分解です。
中央の回路は以下のように実装できます:
def cnot_unitary(distance):
"""Generate a long range CNOT gate using local CNOTs on a 1D
chain of qubits subject to n
nearest-neighbor connections only.
Args:
distance (int) : The distance of the CNOT gate,
with the convention that
a distance of 0 is a nearest-neighbor CNOT.
Returns:
QuantumCircuit: A Quantum Circuit implementing a
long-range CNOT gate
between qubit 0 and qubit distance+1
"""
assert distance >= 0
n = distance # number of qubits between target and control
qr = QuantumRegister(
n + 2, name="q"
) # Circuit with n qubits between control and target
cr = ClassicalRegister(
2, name="cr"
) # Classical register for measuring control and target qubits
qc = QuantumCircuit(qr, cr, name="CNOT_unitary")
control_qubit = 0
qc.h(control_qubit) # Prepare the control qubit in the |+> state
k = int(n / 2)
qc.barrier()
for i in range(control_qubit, control_qubit + k):
qc.cx(i, i + 1)
qc.cx(i + 1, i)
qc.cx(-i - 1, -i - 2)
qc.cx(-i - 2, -i - 1)
if n % 2 == 1:
qc.cx(k + 2, k + 1)
qc.cx(k + 1, k + 2)
qc.barrier()
qc.cx(k, k + 1)
for i in range(control_qubit, control_qubit + k):
qc.cx(k - i, k - 1 - i)
qc.cx(k - 1 - i, k - i)
qc.cx(k + i + 1, k + i + 2)
qc.cx(k + i + 2, k + i + 1)
if n % 2 == 1:
qc.cx(-2, -1)
qc.cx(-1, -2)
return qc
qc_uni = cnot_unitary(distance)
次に、動的回路で行ったのと同様に、、、 基底で測定する回路を構築します。
# Apply the measurement in the XX, YY, and ZZ bases
qc_uni_XX, qc_uni_YY, qc_uni_ZZ = [
measure_in_basis(qc_uni, basis=basis) for basis in ["XX", "YY", "ZZ"]
]
qc_uni_YY.draw(
output="mpl", fold=-1, scale=0.5
) # Circuit for measuring in the YY basis

動的回路とユニタリ回路の両方を小規模な例(distance=6)で構築したので、まずノイズのないシミュレータ上でトランスパイルして実行します。
from qiskit_aer import AerSimulator
aer_backend = AerSimulator()
pm_sim = generate_preset_pass_manager(
optimization_level=0, backend=aer_backend
)
# Dynamic circuits
isa_sim_dyn = pm_sim.run([qc_XX, qc_YY, qc_ZZ])
# Unitary circuits
isa_sim_uni = pm_sim.run([qc_uni_XX, qc_uni_YY, qc_uni_ZZ])
ステップ3:Qiskitプリミティブを使用した実行
これで、ノイズのないシミュレータバックエンドで実験を実行できます。AerSimulatorをバックエンドモードとして使用したQiskit Runtime Samplerで回路を実行します。
sampler_sim = Sampler(mode=aer_backend)
sim_job = sampler_sim.run(isa_sim_dyn + isa_sim_uni)
sim_results = sim_job.result()
ステップ4:後処理を行い、結果を所望の古典的形式で返す
実験が正常に実行された後、測定カウントを後処理して意味のあるメトリクスを抽出します。 このステップでは、以下を行います:
- 長距離CXの性能を評価するための品質メトリクスを定義します。
- 生の測定結果からパウリ演算子の期待値を計算します。
- これらを用いて、生成されたベル状態のフィデリティを算出します。
ノイズのないシミュレーションでは、構築した回路のフィデリティメトリクスが であることを検証します。実際のQPU上の実験では、この解析により動的回路がユニタリ方式のベースライン実装と比較してどの程度良好に動作するかを明確に把握できます。
品質メトリクス
長距離CXプロトコルの成功を評価するために、出力状態が理想的なベル状態にどれだけ近いかを測定します。これを定量化する便利な方法は、パウリ演算子の期待値を用いて状態フィデリティを計算することです。制御量子ビットとターゲット量子ビットにおけるベル状態のフィデリティは、、、およびを知ることで計算できます。具体的には、
生の測定データからこれらの期待値を計算するために、一連のヘルパー関数を定義します:
compute_ZZ_expectation:測定カウントが与えられると、基底における2量子ビットパウリ演算子の期待値を計算します。compute_fidelity:、、の期待値を上記のフィデリティの式に統合します。get_counts_from_bitarray:バックエンドの結果オブジェクトからカウントを抽出するユーティリティです。
def compute_ZZ_expectation(counts):
total = sum(counts.values())
expectation = 0
for bitstring, count in counts.items():
# Ensure bitstring is 2 bits
z1 = (-1) ** (int(bitstring[-1]))
z2 = (-1) ** (int(bitstring[-2]))
expectation += z1 * z2 * count
return expectation / total
def compute_fidelity(counts_xx, counts_yy, counts_zz):
xx, yy, zz = [
compute_ZZ_expectation(c) for c in [counts_xx, counts_yy, counts_zz]
]
return 1 / 4 * (1 + xx - yy + zz)
# Dynamic fidelity
counts_xx = sim_results[0].data.cr.get_counts()
counts_yy = sim_results[1].data.cr.get_counts()
counts_zz = sim_results[2].data.cr.get_counts()
fidelity_dyn = compute_fidelity(counts_xx, counts_yy, counts_zz)
# Unitary fidelity
counts_xx = sim_results[3].data.cr.get_counts()
counts_yy = sim_results[4].data.cr.get_counts()
counts_zz = sim_results[5].data.cr.get_counts()
fidelity_uni = compute_fidelity(counts_xx, counts_yy, counts_zz)
print(f"Dynamic fidelity (distance={distance}): {fidelity_dyn:.4f}")
print(f"Unitary fidelity (distance={distance}): {fidelity_uni:.4f}")
Dynamic fidelity (distance=6): 1.0000
Unitary fidelity (distance=6): 1.0000
ノイズのないシミュレーションでは予想通り、動的回路とユニタリ回路の両方のフィデリティは です。
大規模ハードウェアの例
ここでは、これらすべての詳細を1つのワークフローにまとめ、より大規模なスケールで実際の量子ハードウェア上で実行します。
さまざまな距離の回路を生成する
次に、最大60量子ビット離れたさまざまな量子ビット間距離に対する長距離CX回路を生成します。各距離に対して、、、 基底で測定する回路を構築し、後にフィデリティの計算に使用します。
距離のリストには、短距離と長距離の両方の分離が含まれており、distance = 0 は最近接CXに対応します。これらの同じ距離は、後で比較用の対応するユニタリ回路の生成にも使用されます。
# -------------------------Step 1-------------------------
distances = [
0,
1,
2,
3,
6,
11,
16,
21,
28,
35,
44,
55,
60,
] # Distances for long range CX. distance of 0 is a nearest-neighbor CX
distances.sort()
assert min(distances) >= 0
basis_list = ["XX", "YY", "ZZ"]
# Dynamic circuits
circuits_dyn = []
for distance in distances:
for basis in basis_list:
circuits_dyn.append(
measure_in_basis(lrcx(distance, prep_barrier=False), basis=basis)
)
print(f"Number of circuits: {len(circuits_dyn)}")
# Unitary circuits
circuits_uni = []
for distance in distances:
for basis in basis_list:
circuits_uni.append(
measure_in_basis(cnot_unitary(distance), basis=basis)
)
print(f"Number of circuits: {len(circuits_uni)}")
動的回路とユニタリ回路の両方をさまざまな距離に対して構築したので、トランスパイルの準備が整いました。まずバックエンドデバイスを選択する必要があります。
# -------------------------Step 2-------------------------
# Set up access to IBM Quantum devices
from qiskit.circuit import IfElseOp
service = QiskitRuntimeService()
backend = service.least_busy(
operational=True, simulator=False, min_num_qubits=156
)
次のステップでは、バックエンドが if_else 命令をサポートしていることを確認します。これは動的回路の新しいバージョンに必要です。この機能はまだアーリーアクセス段階にあるため、IfElseOp がまだ利用可能でない場合はバックエンドターゲットに明示的に追加します。
if "if_else" not in backend.target.operation_names:
backend.target.add_instruction(IfElseOp, name="if_else")
1Dチェーン選択のためのレイヤー忠実度文字列の使用
動的回路とユニタリ回路の性能を1Dチェーン上で比較するために、レイヤー忠実度文字列を使用してデバイスから最良の量子ビットチェーンの線形トポロジーを選択します。これにより、両方のタイプの回路が同じ接続制約の下でトランスパイルされ、性能を公平に比較できます。
# This selects best qubits for longest distance and uses
# the same control for all lengths
lf_qubits = backend.properties().to_dict()[
"general_qlists"
] # best linear chain qubits
chosen_layouts = {
distance: [
val["qubits"]
for val in lf_qubits
if val["name"] == f"lf_{distances[-1] + 2}"
][0][: distance + 2]
for distance in distances
}
print(chosen_layouts[max(distances)]) # best qubits at each distance
[11, 12, 13, 14, 15, 19, 35, 34, 33, 39, 53, 54, 55, 59, 75, 74, 73, 72, 71, 70, 69, 68, 67, 66, 65, 64, 63, 62, 61, 76, 81, 82, 83, 84, 85, 86, 87, 97, 107, 108, 109, 110, 111, 98, 91, 92, 93, 94, 95, 99, 115, 114, 113, 119, 133, 132, 131, 138, 151, 150, 149, 148]
isa_circuits_dyn = []
isa_circuits_uni = []
# Using the same initial layouts for both circuits for better
# apples to apples comparison
for qc in circuits_dyn:
pm = generate_preset_pass_manager(
optimization_level=1,
backend=backend,
initial_layout=chosen_layouts[qc.num_qubits - 2],
)
isa_circuits_dyn.append(pm.run(qc))
for qc in circuits_uni:
pm = generate_preset_pass_manager(
optimization_level=1,
backend=backend,
initial_layout=chosen_layouts[qc.num_qubits - 2],
)
isa_circuits_uni.append(pm.run(qc))
print(
f"2Q depth: "
f"{isa_circuits_dyn[14].depth(lambda x: x.operation.num_qubits == 2)}"
)
isa_circuits_dyn[14].draw("mpl", fold=-1, idle_wires=0)
2Q depth: 2
print(
f"2Q depth: "
f"{isa_circuits_uni[14].depth(lambda x: x.operation.num_qubits == 2)}"
)
isa_circuits_uni[14].draw("mpl", fold=-1, idle_wires=False)
2Q depth: 13

LRCX回路で使用される量子ビットの可視化
このセクションでは、LRCX回路がハードウェアにどのようにマッピングされるかを調べます。まず、回路で使用される物理量子ビットを可視化し、次にレイアウト上での制御ビットとターゲットビット間の距離が操作数にどのような影響を与えるかを検討します。
# Note: the qubit coordinates must be hard-coded.
# The backend API does not currently provide this information directly.
# If using a different backend, you will need to
# adjust the coordinates accordingly,
# or set the qubit_coordinates = None to use the default layout coordinates.
def _heron_coords_r2():
"""Generate coordinates for the Heron layout in R2. Note"""
cord_map = np.array(
[
[
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
3,
7,
11,
15,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
1,
5,
9,
13,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
3,
7,
11,
15,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
1,
5,
9,
13,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
3,
7,
11,
15,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
1,
5,
9,
13,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
3,
7,
11,
15,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
],
-1
* np.array([j for i in range(15) for j in [i] * [16, 4][i % 2]]),
],
dtype=int,
)
hcords = []
ycords = cord_map[0]
xcords = cord_map[1]
for i in range(156):
hcords.append([xcords[i] + 1, np.abs(ycords[i]) + 1])
return hcords
# Visualize the active qubits in the circuit layout
plot_circuit_layout(
circuit=isa_circuits_uni[-1],
backend=backend,
view="physical",
qubit_coordinates=_heron_coords_r2(),
)
次に、実際のバックエンドで実験を実行します。また、バッチ処理を活用して、複数の試行にわたる実験を効率的に実行します。試行を繰り返すことで、ユニタリ方式とダイナミック方式のより正確な比較のための平均値を計算できるほか、各実行間の偏差を比較することでそれらのばらつきを定量化することができます。
# -------------------------Step 3-------------------------
num_trials = 10
jobs_uni = []
jobs_dyn = []
with Batch(backend=backend) as batch:
sampler = Sampler(mode=batch)
sampler.options.environment.job_tags = ["TUT_LRE"]
for _ in range(num_trials):
jobs_uni.append(sampler.run(isa_circuits_uni, shots=1024))
jobs_dyn.append(sampler.run(isa_circuits_dyn, shots=1024))
動的長距離CX回路のフィデリティを計算します。各距離について、、、基底における測定結果を抽出します。これらの結果を、先ほど定義したヘルパー関数を使用してに従ってフィデリティを算出します。これにより、各距離における動的プロトコルの観測フィデリティが得られます。
# -------------------------Step 4-------------------------
fidelities_dyn = []
# loop over trials
for job in jobs_dyn:
result_dyn = job.result()
trial_fidelities = []
# loop over all distances
for ind, dist in enumerate(distances):
counts_xx = result_dyn[ind * 3].data.cr.get_counts()
counts_yy = result_dyn[ind * 3 + 1].data.cr.get_counts()
counts_zz = result_dyn[ind * 3 + 2].data.cr.get_counts()
trial_fidelities.append(
compute_fidelity(counts_xx, counts_yy, counts_zz)
)
fidelities_dyn.append(trial_fidelities)
# average over trials for each distance
avg_fidelities_dyn = np.mean(fidelities_dyn, axis=0)
std_fidelities_dyn = np.std(fidelities_dyn, axis=0)
次に、ユニタリ長距離CX回路のフィデリティを計算します。上記の動的回路と同じ方法で行います。
fidelities_uni = []
# loop over trials
for job in jobs_uni:
result_uni = job.result()
trial_fidelities = []
# loop over all distances
for ind, dist in enumerate(distances):
counts_xx = result_uni[ind * 3].data.cr.get_counts()
counts_yy = result_uni[ind * 3 + 1].data.cr.get_counts()
counts_zz = result_uni[ind * 3 + 2].data.cr.get_counts()
trial_fidelities.append(
compute_fidelity(counts_xx, counts_yy, counts_zz)
)
fidelities_uni.append(trial_fidelities)
# average over trials for each distance
avg_fidelities_uni = np.mean(fidelities_uni, axis=0)
std_fidelities_uni = np.std(fidelities_uni, axis=0)
結果のプロット
結果を視覚的に把握するために、以下のセルでは、エンタングルされた量子ビット間の距離を変化させた場合に測定された推定ゲートフィデリティを各手法についてプロットします。
fig, ax = plt.subplots()
# Unitary with error bars
ax.errorbar(
distances,
avg_fidelities_uni,
yerr=std_fidelities_uni,
fmt="o-.",
color="c",
ecolor="c",
elinewidth=1,
capsize=4,
label="Unitary",
)
# Dynamic with error bars
ax.errorbar(
distances,
avg_fidelities_dyn,
yerr=std_fidelities_dyn,
fmt="o-.",
color="m",
ecolor="m",
elinewidth=1,
capsize=4,
label="Dynamic",
)
# Random gate baseline
ax.axhline(y=1 / 4, linestyle="--", color="gray", label="Random gate")
legend = ax.legend(frameon=True)
for text in legend.get_texts():
text.set_color("black")
legend.get_frame().set_facecolor("white")
legend.get_frame().set_edgecolor("black")
ax.set_title(
"Bell State Fidelity vs Control–Target Separation", color="black"
)
ax.set_xlabel("Distance", color="black")
ax.set_ylabel("Bell state fidelity", color="black")
ax.grid(linestyle=":", linewidth=0.6, alpha=0.4, color="gray")
ax.set_ylim((0.2, 1))
ax.set_facecolor("white")
fig.patch.set_facecolor("white")
for spine in ax.spines.values():
spine.set_visible(True)
spine.set_color("black")
ax.tick_params(axis="x", colors="black")
ax.tick_params(axis="y", colors="black")
plt.show()
上記のフィデリティプロットから、LRCXは直接的なユニタリ実装を一貫して上回ることはできませんでした。実際、制御-ターゲット間の距離が短い場合、ユニタリ回路の方がより高いフィデリティを達成しました。しかし、距離が大きくなると、動的回路はユニタリ実装よりも良好なフィデリティを達成し始めます。この振る舞いは現在のハードウェアでは予想外のものではありません。動的回路は長いSWAPチェーンを回避することで回路の深さを削減しますが、回路中測定、古典的フィードフォワード、および制御パスの遅延による追加の回路時間が発生します。この追加レイテンシにより、デコヒーレンスおよび読み出しエラーが増加し、短距離では深さの削減による利点を上回る可能性があります。
それにもかかわらず、動的アプローチがユニタリアプローチを上回る交差点が観測されます。これは異なるスケーリング特性の直接的な結果です。ユニタリ回路の深さは量子ビット間の距離に対して線形に増加しますが、動的回路の深さは一定に保たれます。
要点:
- 動的回路の直接的な利点: 現時点での主な動機は、2量子ビットの深さの削減であり、必ずしもフィデリティの向上ではありません。
- 現在フィデリティが低下する理由: 測定および古典的操作による回路時間の増加が支配的となることが多く、特に制御-ターゲット間の距離が小さい場合に顕著です。
- 今後の展望: ハードウェアが改善されるにつれて、具体的にはより高速な読み出し、より短い古典制御レイテンシ、および回路中オーバーヘッドの削減により、これらの深さと実行時間の削減が測定可能なフィデリティの向上につながることが期待されます。
# Compute metrics for each distance, skipping the basis circuits since
# they are identical for each distance
depths_2q_dyn = [
c.depth(lambda x: x.operation.num_qubits == 2)
for c in isa_circuits_dyn[::3]
]
meas_dyn = [
sum(1 for instr in c.data if instr.operation.name == "measure")
for c in isa_circuits_dyn[::3]
]
depths_2q_uni = [
c.depth(lambda x: x.operation.num_qubits == 2)
for c in isa_circuits_uni[::3]
]
meas_uni = [
sum(1 for instr in c.data if instr.operation.name == "measure")
for c in isa_circuits_uni[::3]
]
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].plot(
distances, depths_2q_uni, "o-.", color="c", label="Unitary (2Q depth)"
)
axes[0].plot(
distances, depths_2q_dyn, "o-.", color="m", label="Dynamic (2Q depth)"
)
axes[0].set_xlabel("Number of qubits between control and target")
axes[0].set_ylabel("Two-qubit depth")
axes[0].grid(True, linestyle=":", linewidth=0.6, alpha=0.4)
axes[0].legend()
axes[1].plot(
distances, meas_uni, "o-.", color="c", label="Unitary (# measurements)"
)
axes[1].plot(
distances, meas_dyn, "o-.", color="m", label="Dynamic (# measurements)"
)
axes[1].set_xlabel("Number of qubits between control and target")
axes[1].set_ylabel("Number of measurements")
axes[1].grid(True, linestyle=":", linewidth=0.6, alpha=0.4)
axes[1].legend()
fig.suptitle("Scaling of Unitary vs Dynamic LRCX with Distance", fontsize=12)
plt.tight_layout()
plt.show()
この2量子ビット深さのプロットは、動的回路で実装されたLRCXの主要な利点を示しています。制御量子ビットとターゲット量子ビットの間の距離が増加しても、性能は本質的に一定に保たれます。一方、ユニタリ実装は、必要なSWAPチェーンにより距離に対して線形に増加します。深さは2量子ビット操作の論理的なスケーリングを捉え、測定回数は動的回路の追加オーバーヘッドを反映します。これらの測定は並列で実行されるため効率的ですが、現在のハードウェアでは依然として固定コストが発生します。
現在フィデリティが低下する理由:測定および古典的操作による回路時間の増加が支配的となることが多く、特に制御-ターゲット間の距離が小さい場合に顕著です。例えば、Heron r2プロセッサの平均読み出し長は2,280 nsであるのに対し、2量子ビットゲート長はわずか68 nsです。
測定および古典的レイテンシが改善されるにつれて、動的回路の一定深さおよび一定測定回数のスケーリングにより、より大規模な回路において明確なフィデリティおよび実行時間の優位性がもたらされることが期待されます。
次のステップ
この研究に興味を持たれた方は、以下の資料もご覧ください:
参考文献
[1] Efficient Long-Range Entanglement using Dynamic Circuits, by Elisa Bäumer, Vinay Tripathi, Derek S. Wang, Patrick Rall, Edward H. Chen, Swarnadeep Majumder, Alireza Seif, Zlatko K. Minev. IBM Quantum, (2023). https://arxiv.org/abs/2308.13065