データエンコーディング
はじめに・表記法
量子アルゴリズムを使用するためには、古典データを何らかの方法で量子回路に取り込む必要があります。これは一般的にデータのエンコーディングと呼ばれますが、データのローディングと呼ばれることもあります。前のレッスンで学んだ特徴マッピング(feature mapping)の概念を思い出してください。特徴マッピングとは、データの特徴をある空間から別の空間へ写す写像です。古典データを量子コンピューターに転送すること自体もある種のマッピングであり、特徴マッピングと呼ぶことができます。実際には、Qiskitに組み込まれている特徴マッピング(z_feature_map や zz_feature_map など)は通常、回転層とエンタングリング層を含み、状態をヒルベルト空間の多くの次元へ拡張します。このエンコーディングプロセスは量子機械学習アルゴリズムの重要な部分であり、その計算能力に直接影響します。
以下に紹介するエンコーディング手法の中には、古典的に効率よくシミュレートできるものもあります。これはとくに、積状態(つまり、量子ビットをエンタングルしない)を生成するエンコーディング手法で容易に確認できます。また、量子的な優位性は、データセットの量子的な複雑さとエンコーディング手法が適切に一致している場合に生まれる可能性が高いことを覚えておいてください。そのため、独自のエンコーディング回路を作成することになる可能性が非常に高いです。ここでは、様々なエンコーディング戦略を比較対照できるように、また何が可能かを示すために、幅広い手法を紹介します。エンコーディング手法の有用性については、いくつか非常に一般的な言明が可能です。たとえば、完全なエンタングリングスキームを持つ efficient_su2(以下参照)は、積状態を生成する手法(z_feature_map など)よりも、データの量子的特徴を捉える可能性がはるかに高いです。しかしそれは、efficient_su2 があなたのデータセットに対して十分、あるいは十分に適合していて、量子スピードアップをもたらすということを意味するわけではありません。それは、モデル化または分類されるデータの構造を慎重に考慮する必要があります。また、回路の深さとのトレードオフもあります。回路内の量子ビットを完全にエンタングルする多くの特徴マップは非常に深い回路を生成し、現在の量子コンピューターで使用可能な結果を得るには深すぎる場合があります。
表記法
データセットは 個のデータベクトルの集合です:。各ベクトルは 次元、つまり です。これは複素数のデータ特徴にも拡張できます。このレッスンでは、全体の集合 やその特定の要素 などの表記を使用することがあります。しかし、ほとんどの場合、データセットから1度に1つのベクトルをロードすることを想定し、 個の特徴を持つ単一のベクトルを単に と表記することが多いです。
また、 という記号でデータベクトル の特徴マッピング を表すのが一般的です。特に量子コンピューティングでは、量子コンピューティングにおける写像を という表記で表すことが多く、これはこれらの操作のユニタリな性質を強調しています。どちらも特徴マッピングであるため、同じ記号を使うことも正確です。このコースでは次のように使い分けます:
- :機械学習における特徴マッピング全般を議論する際、
- :特徴マッピングの回路実装を議論する際。
正規化と情報損失
古典的機械学習では、訓練データの特徴を「正規化」またはスケール変換することが多く、これによりモデルの性能が向上することがよくあります。一般的な方法の一つは、最小-最大正規化(min-max normalization)または標準化(standardization)を使うことです。最小-最大正規化では、データ行列 の特徴列(たとえば特徴 )を次のように正規化します:
ここで min と max は、データセット 内の 個のデータベクトルにわたる特徴 の最小値と最大値を指します。すべての特徴値は単位区間内に収まります:(すべての 、 について)。
正規化は量子力学・量子コンピューティングにおいても基本的な概念ですが、最小-最大正規化とは少し異なります。量子力学における正規化では、状態ベクトル の長さ(量子コンピューティングの文脈では2-ノルム)が1に等しいことが要求されます:。これにより測定確率の和が1になります。状態は2-ノルムで割ることで正規化されます。すなわち、次のようにスケール変換します:
量子コンピューティングおよび量子力学では、これは人間がデータに課す正規化ではなく、量子状態の根本的な性質です。エンコーディング方式によっては、この制約がデータのスケール変換に影響する場合があります。たとえば、振幅エンコーディング(以下参照)では、量子力学の要請により となるようにデータベクトルが正規化され、これはエンコードされるデータのスケーリングに影響します。位相エンコーディングでは、量子ビットの位相角へのエンコーディングによる modulo- 効果による情報損失を防ぐために、特徴値を となるようにスケール変換することが推奨されています[1,2]。
エンコーディングの方法
次のいくつかのセクションでは、 個のデータベクトル(それぞれ 個の特徴を持つ)からなる小さな例の古典データセット を参照します:
上で導入した表記法を使うと、たとえば集合 の第4データベクトルの第1特徴は と表せます。
基底エンコーディング
基底エンコーディングは、古典的な ビット列を 量子ビット系の計算基底状態にエンコードします。たとえば を考えます。これは4ビット列 として表現でき、4量子ビット系では量子状態 として表されます。より一般的に、 ビット列: に対して、対応する 量子ビット状態は (、)です。これは単一の特徴に対するものであることに注意してください。
量子コンピューティングにおける基底エンコーディングは、各古典ビットを個別の量子ビットとして表現し、データの2進数表現を計算基底の量子状態に直接マッピングします。複数の特徴をエンコードする必要がある場合、各特徴はまず2進数形式に変換され、次に個別の量子ビットグループに割り当てられます(特徴ごとに1グループ)。各量子ビットはその特徴の2進数表現における1ビットを反映します。
例として、ベクトル (5, 7, 0) をエンコードしましょう。
すべての特徴が4ビットで格納されているとします(必要以上ですが、1桁の10進整数を任意に表現するには十分です):
5 → 2進数 0101
7 → 2進数 0111
0 → 2進数 0000
これらのビット列はそれぞれ4量子ビットの3つのグループに割り当てられるため、全体の12量子ビット基底状態は次のようになります:
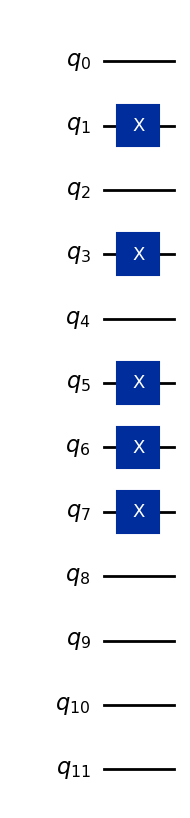
ここで、最初の4量子ビットが第1特徴、次の4量子ビットが第2特徴、最後の4量子ビットが第3特徴を表します。以下のコードは、データベクトル (5,7,0) を量子状態に変換し、他の1桁の特徴にも汎用化されています。
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
理解度チェック
以下の問いを読んで答えを考えてから、三角印をクリックして解答を確認してください。
例のデータセット の第1ベクトルをエンコードするコードを書いてください:
基底エンコーディングを使用して。
解答:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
振幅エンコーディング
振幅エンコーディングは、データを量子状態の振幅にエンコードします。正規化された古典的な 次元データベクトル を、 量子ビット量子状態 の振幅として表現します:
ここで は前と同じデータベクトルの次元数、 は の 番目の要素、 は 番目の計算基底状態です。 はエンコードするデータから決定される正規化定数です。これは量子力学が課す正規化条件です:
一般に、これは各特徴についてすべてのデータベクトルにわたって行う最小-最大正規化とは異なる条件です。これをどのように扱うかは問題によって異なりますが、上記の量子力学的な正規化条件は避けて通れません。
振幅エンコーディングでは、データベクトルの各特徴が異なる量子状態の振幅として格納されます。 量子ビット系は 個の振幅を提供するため、 個の特徴の振幅エンコーディングには 量子ビットが必要です。
例として、例のデータセット の第1ベクトル を振幅エンコーディングでエンコードしてみましょう。得られたベクトルを正規化すると:
となり、結果として得られる2量子ビット量子状態は:
上の例では、ベクトルの特徴数 は2の累乗ではありません。 が2の累乗でない場合は、 を満たす量子ビット数 を選び、振幅ベクトルを情報を持たない定数(ここではゼロ)で埋めます。
基底エンコーディングと同様に、データセットをエンコードする状態を計算したら、Qiskitの initialize 関数を使ってそれを準備することができます:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

振幅エンコーディングの利点は、前述のとおりエンコードに必要な量子ビット数が 個だけで済むことです。しかし、後続のアルゴリズムは量子状態の振幅に対して演算する必要があり、量子状態の準備・測定の手法は一般に効率的ではない傾向があります。
理解度チェック
以下の問いを読んで答えを考えてから、三角印をクリックして解答を確認してください。
以下のベクトル(例のデータセットから2つのベクトルを組み合わせたもの)のエンコードに対して、正規化された状態を書き下してください:
振幅エンコーディングを使用して。
解答:
6つの数をエンコードするには、振幅をエンコードできる状態が少なくとも6つ必要です。これには3量子ビットが必要です。未知の正規化因子 を使って、次のように書けます:
なお、
したがって、
同じデータベクトル に対して、振幅エンコーディングを使ってこれらのデータ特徴をロードする回路を作成するコードを書いてください。
解答:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

非常に大きなデータベクトルを扱う必要があるかもしれません。次のベクトルを考えてください:
正規化を自動化し、振幅エンコーディングのための量子回路を生成するコードを書いてください。
解答:
多くの可能な解答があります。以下は途中のいくつかのステップを出力するコードです:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
振幅エンコーディングは基底エンコーディングに比べて優れている点がありますか?あれば説明してください。
解答:
いくつかの答えが考えられます。一つの答えは、基底状態の固定された順序があるため、この振幅エンコーディングはエンコードされた数値の順序を保持するということです。また、多くの場合、より密にエンコードされることになります。
振幅エンコーディングの利点は、 次元( 特徴)のデータベクトル のエンコードに 量子ビットしか必要としないことです。しかし、振幅エンコーディングは一般に非効率な手続きであり、任意の状態準備が必要で、CNOTゲートの数が指数関数的になります。言い換えると、状態準備の多項式実行時間複雑性は次元数に対して (ここで 、 は量子ビット数)です。振幅エンコーディングは「空間における指数的な節約を、時間における指数的な増大のコストで提供する」[3]ものです。ただし、特定のケースでは実行時間を に改善できる場合もあります[4]。エンドツーエンドの量子スピードアップのためには、データロードの実行時間複雑性を考慮する必要があります。
角度エンコーディング
角度エンコーディングは、量子サポートベクターマシン(QSVM)や変分量子回路(VQC)など、Pauliフィーチャーマップを使用する多くのQMLモデルで注目されています。角度エンコーディングは、以下で紹介する位相エンコーディングや高密度角度エンコーディングと密接に関連しています。ここでは「角度エンコーディング」を、軸からの回転、すなわち例えばゲートやゲートによって実現されるにおける回転を指す用語として使います[1,3]。実際には、任意の回転またはその組み合わせでデータをエンコードすることができますが、が文献でよく使われるため、ここではそれを重点的に説明します。
単一の量子ビットに適用すると、角度エンコーディングはデータ値に比例したY軸回転を与えます。データセット内の番目のデータベクトルの単一の(番目の)特徴量 のエンコーディングについて考えてみましょう:
あるいは、ゲートを使って角度エンコーディングを行うこともできますが、エンコードされた状態はと比べて複素相対位相を持つことになります。
角度エンコーディングは、前述の2つの方法とはいくつかの点で異なります。角度エンコーディングでは:
- 各特徴量の値が対応する量子ビットにマッピングされ()、量子ビットは積状態のままです。
- データ点の特徴量全体ではなく、1つの数値が一度にエンコードされます。
- 個のデータ特徴量に対して個の量子ビットが必要です()。多くの場合、等号が成立します。がどのように可能かは、次のいくつかのセクションで見ていきます。
- 生成される回路は一定の深さを持ちます(トランスパイル前の深さは通常1です)。
一定の深さの量子回路は、現在の量子ハードウェアに特に適しています。を使ってデータをエンコードするもう1つの特徴(特にY軸角度エンコーディングを選択した場合)は、特定の用途に有用な実数値の量子状態を生成することです。Y軸回転の場合、実数値の角度によってY軸回転ゲートでデータがマッピングされます(Qiskit RYGate)。位相エンコーディング(後述)と同様に、情報損失やその他の望ましくない影響を防ぐため、となるようにデータをスケール変換することをお勧めします。
以下のQiskitコードは、単一の量子ビットを初期状態からデータ値をエンコードするように回転させます。
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
状態ベクトルへの作用を可視化するための関数を定義します。関数定義の詳細は重要ではありませんが、状態ベクトルとその変化を可視化できることは重要です。
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

これは単一のデータベクトルの1つの特徴量に過ぎませんでした。番目のデータベクトルに対して個の特徴量を個の量子ビットの回転角にエンコードする場合、エンコードされた積状態は次のようになります:
これは次の式と等価であることに注意してください:
理解度チェック
以下の問題を読み、答えを考えてから、三角形をクリックして解答を確認してください。
上記の方法に従い、角度エンコーディングを使ってデータベクトル をエンコードしてください。
解答:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

上記の角度エンコーディングを使って5つの特徴量をエンコードするには、何個の量子ビットが必要ですか?
解答: 5
位相エンコーディング
位相エンコーディングは、上述の角度エンコーディングと非常に似ています。量子ビットの位相角は、+軸から軸回りの実数値の角度です。データは位相回転でマッピングされ、です(詳細はQiskit PhaseGateを参照)。情報損失やその他の望ましくない影響を防ぐため、となるようにデータをスケール変換することをお勧めします[1,2]。
量子ビットはよく状態に初期化されますが、これは位相回転演算子の固有状態であるため、位相エンコーディングを実装するためにはまず量子ビットの状態を回転させる必要があります。そのため、アダマールゲートで状態を初期化することが適切です:。単一量子ビットへの位相エンコーディングは、データ値に比例した相対位相を与えることを意味します:
位相エンコーディングの手順は、各特徴量の値を対応する量子ビットの位相にマッピングします()。全体として、位相エンコーディングのアダマール層を含む回路深さは2であり、効率的なエンコーディング方式となっています。位相エンコードされた多量子ビット状態(個の特徴量に対して個の量子ビット)は積状態です:
以下のQiskitコードは、まずアダマールゲートで単一量子ビットの初期状態を準備し、次に位相ゲートを使って再度回転させ、データ特徴量をエンコードします。
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

先ほど定義したplot_Nstates関数を使って、における回転を可視化することができます。
plot_Nstates(states, axis=None, plot_trace_points=True)

ブロッホ球のプロットは、でのZ軸回転を示しています。薄緑色の矢印が最終状態を示しています。
位相エンコーディングは、特におよびフィーチャーマップや、一般的なPauliフィーチャーマップなど、多くの量子フィーチャーマップで使用されています。
理解度チェック
以下の問題を読み、答えを考えてから、三角形をクリックして解答を確認してください。
上記の位相エンコーディングを使って8つの特徴量を保存するには、何個の量子ビットが必要ですか?
解答: 8
位相エンコーディングを使ってベクトル をエンコードするコードを書いてください。
解答:
答えは多数あるかもしれません。こちらは一例です:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

高密度角度エンコーディング
高密度角度エンコーディング(DAE)は、角度エンコーディングと位相エンコーディングを組み合わせたものです。DAEでは、1つの量子ビットに2つの特徴量の値をエンコードすることができます:1つをY軸回転角で、もう1つを軸回転角で: 。2つの特徴量を次のようにエンコードします:
2つのデータ特徴量を1つの量子ビットにエンコードすることで、エンコードに必要な量子ビット数が削減されます。これをより多くの特徴量に拡張すると、データベクトルは次のようにエンコードできます:
DAEは、ここで使われている正弦波関数の代わりに、2つの特徴量の任意の関数に一般化することができます。これは一般量子ビットエンコーディング[7]と呼ばれています。
DAEの例として、以下のコードは特徴量とのエンコーディングを行い、可視化します。
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

理解度チェック
以下の問題を読み、答えを考えてから、三角形をクリックして解答を確認してください。
上記の説明に基づいて、高密度エンコーディングを使って6つの特徴量をエンコードするには何個の量子ビットが必要ですか?
解答: 3
高密度角度エンコーディングを使ってベクトル をロードするコードを書いてください。
解答:
エンコーディングスキームで未使用のパラメーターが1つ残る問題を避けるため、リストに「0」をパディングしていることに注意してください。
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

組み込みフィーチャーマップによるエンコーディング
任意の点でのエンコーディング
角度エンコーディング、位相エンコーディング、高密度エンコーディングはいずれも、各量子ビットに特徴量をエンコードした積状態(または1量子ビットに2特徴量)を準備します。これは基底エンコーディングや振幅エンコーディングとは異なります。それらの方法はエンタングル状態を利用するため、データ特徴量と量子ビットの間に1対1の対応関係がありません。振幅エンコーディングでは、例えば、ある特徴量が状態の振幅として、別の特徴量がの振幅として格納されることがあります。一般的に、積状態でエンコードする方法は浅い回路になり、各量子ビットに1〜2個の特徴量を格納できます。エンタングルメントを利用して量子ビットではなく状態に特徴量を関連付ける方法は、より深い回路になりますが、平均的に1量子ビットあたりより多くの特徴量を格納できます。
しかし、エンコーディングは振幅エンコーディングのように完全に積状態である必要も、完全にエンタングル状態である必要もありません。実際、Qiskitに組み込まれている多くのエンコーディングスキームでは、最初だけでなく、エンタングル層の前後にもデータをエンコードすることができます。これは「データ再アップロード」として知られています。関連する研究については、参考文献[5]および[6]を参照してください。
このセクションでは、いくつかの組み込みエンコーディングスキームを使用して可視化します。このセクションのすべての方法は、個の量子ビット上の個のパラメーター化ゲートの回転として個の特徴量をエンコードします()。特定の量子ビット数に対してデータロードを最大化することが唯一の考慮事項ではないことに注意してください。多くの場合、回路の深さは量子ビット数よりもさらに重要な考慮事項となります。
Efficient SU2
エンタングルメントを用いたエンコードの一般的かつ有用な例として、Qiskit の efficient_su2 回路があります。この回路は、例えばわずか 2 量子ビットで 8 個の特徴量をエンコードできるという優れた特性を持っています。まずこれを確認し、どのようにして可能なのかを理解してみましょう。
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

状態を記述する際、Qiskit の慣例に従い、最下位の量子ビットを または のように右端に配置します。このような状態はすぐに非常に複雑になるため、状態を陽に書き下すことはほとんど行われません。この稀な例がその理由を説明するのに役立つでしょう。
系は 状態から始まります。最初のバリア( と表記する地点)までの状態は次のようになります。
これはすでに見たデンスエンコードです。次に CNOT ゲートを経て、2 番目のバリア()での状態は次のようになります。
最後の 1 量子ビット回転を適用して同じ状態をまとめると、次の最終状態が得られます。
これは解析するには複雑すぎるでしょう。代わりに、状態に格納したパラメータ数を振り返ってみましょう:8 個です。しかし計算基底の状態は 4 つしかありません。一見すると、最終状態が と書けるため、パラメータが多すぎるように思えるかもしれません。しかし各係数が複素数であることに注目してください。次のように書くと:
状態上に 8 個の特徴量をエンコードするための 8 個のパラメータが確かに存在することがわかります。
量子ビット数を増やすか、エンタングルメント層と回転層の繰り返し数を増やすことで、さらに多くのデータをエンコードできます。波動関数を書き下すことはすぐに手に負えなくなりますが、エンコードの様子は引き続き確認できます。
次に、12 個の特徴量を持つデータベクトル を、3 量子ビットの efficient_su2 回路にエンコードします。各パラメータ化ゲートが異なる特徴量をエンコードします。
このデータベクトルでは、特徴量が特定の順序で示されています。単独で見ると、この順序でエンコードするか逆順でエンコードするかは問題ではありません。重要なのは、その順序を把握して一貫性を保つことです。回路図において efficient_su2 は特定のエンコード順序を前提としており、具体的には量子ビット 0 から量子ビット 2 の順で最初の層のパラメータ化ゲートを埋め、次の層に移ります。これはリトルエンディアン記法と一致するわけでも矛盾するわけでもありません。エンコード回路を指定する前の段階では、データの特徴量をクビット順に a priori に並べることはできないためです。
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

量子ビット数を増やす代わりに、エンタングルメント層と回転層の繰り返し数を増やすことも選択できます。ただし、有効な繰り返し数には限りがあります。 前述のとおり、トレードオフが存在します。量子ビット数や繰り返し数が多い回路はより多くのパラメータを格納できますが、回路の深さが増大します。組み込みフィーチャーマップの深さについては後ほど改めて取り上げます。 次に紹介するいくつかのエンコード手法は、Qiskit に組み込まれており、名称に「フィーチャーマップ」が含まれています。ここで改めて確認しておきたいのは、データを量子回路にエンコードすること が フィーチャーマッピングであるという点です。つまり、データを新しい空間、すなわち関連する量子ビットのヒルベルト空間に写像します。元の特徴量空間の次元とヒルベルト空間の次元の関係は、エンコードに使用する回路によって異なります。
フィーチャーマップ
フィーチャーマップ(ZFM)は、位相エンコードの自然な拡張として解釈できます。ZFM は 1 量子ビットゲートの層が交互に配置された構造で、アダマールゲート層と位相ゲート層から成ります。データベクトル が 個の特徴量を持つとします。フィーチャーマッピングを行う量子回路は、初期状態に作用するユニタリ演算子として次のように表されます。
ここで は 量子ビットの基底状態です。この記法は参考文献 [4] の Havlicek et al. との整合性のために用いています。データの特徴量 は対応する量子ビットに 1 対 1 で写像されます。例えば、データベクトルに 8 個の特徴量がある場合、8 量子ビットを使用します。ZFM 回路は、アダマールゲート層と位相ゲート層から成るサブ回路を 回繰り返して構成されます。アダマール層とは、 量子ビットレジスタ内のすべての量子ビットにアダマールゲートを同時に作用させるもので、 と表されます。これと同様に、位相ゲート層は 番目の量子ビットに を作用させたもので、各 ゲートは 1 つの特徴量を引数として取りますが、位相ゲート層()はデータベクトルの関数です。1 回の繰り返しによる ZFM 回路の全体ユニタリは次のようになります。
このユニタリを 回繰り返すと次のようになります。
データの特徴量 は、 回のすべての繰り返しにおいて同じ方法で位相ゲートに写像されます。ZFM のフィーチャーマップ状態は積状態であり、古典シミュレーションが効率的に行えます [4]。
小さな例から始めるために、2 量子ビットの ZFM 回路を Qiskit でコーディングし、シンプルな回路構造を確認します。この例では、データベクトル を用いて 1 回の繰り返し を実装します。これは Python のベクトルの標準的な順序で記述されており、 番目の要素は です。この 番目の特徴量を 番目の量子ビットにエンコードすることも、 番目の量子ビットにエンコードすることも自由です。ただし、特徴量の順序と量子ビットの順序の間に常に 1 対 1 の写像があるとは限りません。フィーチャーマップごとに各量子ビットにエンコードされる特徴量の数が異なるためです。再度強調しますが、重要なのは各特徴量がどこにエンコードされているかを把握することです。 フィーチャーマップにパラメータリストを渡す場合、リストの 0 番目の特徴量がパラメータ化ゲートを持つ最下位量子ビット(量子ビット 0)にエンコードされます。したがって、手動で行う際もその慣例に従います。 を 番目の量子ビットに、 を 番目の量子ビットにエンコードします。
ZFM 回路のユニタリ演算子は次のように初期状態に作用します。
各量子ビットへの演算を強調するために、テンソル積の周りで式を整理しています。次の Qiskit コードでは、ZFM の構造を示すためにアダマールゲートと位相ゲートを明示的に使用しています。
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

次に、同じデータベクトル を、3 回の繰り返し を持つ ZFM 回路にエンコードします。Qiskit の z_feature_map クラスを使用することで、量子フィーチャーマップ が得られます。z_feature_map クラスのデフォルトでは、パラメータ は位相ゲートに写像される前に 2 倍されます()。上記と同じエンコードを再現するために、2 で割ります。
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

これは明らかに上で手動で行ったものとは異なる写像ですが、パラメータの順序については一貫性があります。 は再び 番目の量子ビットにエンコードされています。
ZFM は Qiskit の ZFM クラスを通じて使用できますが、この構造を参考にして独自のフィーチャーマッピングを構築することも可能です。
フィーチャーマップ
フィーチャーマップ(ZZFM)は、2 量子ビットのエンタングルメントゲート、具体的には -回転ゲート を含めることで ZFM を拡張したものです。ZZFM は ZFM とは異なり、古典コンピュータでの計算が一般に困難であると予想されています。
は 相互作用を実装し、 のとき最大エンタングルメント状態になります。 は次の Qiskit コードに示すように、RZZ ゲート と QuantumCircuit クラスの decompose メソッドを使って 2 量子ビット上のゲートの系列に分解できます。ここではデータベクトル の 1 つの特徴量 をエンコードします。
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

よくあるように、.decompose() を使って構成ゲートをすべて確認するまでは、1 つのゲートのような単位として表示されます。
qc.decompose().draw("mpl", scale=1)

データは 2 番目の量子ビット上の位相回転 によって写像されます。 ゲートは、エンコードされた特徴量の値によって決まるエンタングルメントの度合いで、作用する 2 つの量子ビットをエンタングルさせます。
完全な ZZFM 回路は、ZFM と同様のアダマールゲートと位相ゲートに続いて、上で説明したエンタングルメントで構成されます。ZZFM 回路の 1 回の繰り返しは次のようになります。
ここで はエンタングルメントスキームによって構造化された ZZ ゲート層を含みます。いくつかのエンタングルメントスキームを後のコードブロックで示します。 の構造には、エンタングルされる量子ビットのデータ特徴量を組み合わせる関数も含まれています。 ゲートを量子ビット と に適用するとします。位相層では、これらの量子ビットにはそれぞれ と をエンコードする位相ゲートが作用します。 の引数 は、これらの特徴量のどちらか一方ではなく、(方位角と混同しないよう注意)と表記されることが多い関数になります。
以下のいくつかの例でこれを確認します。複数回の繰り返しへの拡張は z_feature_map の場合と同様です。
演算子の複雑さが増したため、まず次のコードを使って 2 量子ビット ZZFM と 1 回の繰り返しでデータベクトル をエンコードします。
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

Qiskit のデフォルトでは、特徴量 はこの写像関数 によって に一緒に写像されます。Qiskit では、前処理ステップとして関数 (または 、ここで は ゲートを通じて結合される量子ビットペアの集合)をユーザーがカスタマイズできます。
4 次元のデータベクトル に移り、1 回の繰り返しを持つ 4 量子ビット ZZFM に写像すると、様々な量子ビットペアに対する写像 を確認できるようになります。また、「線形」エンタングルメントの意味も理解できます。
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

線形エンタングルメントスキームでは、この回路内で番号が隣接する量子ビットのペアがエンタングルされます。Qiskit には、circular(円形)や full(全結合)など、他の組み込みエンタングルメントスキームもあります。
パウリフィーチャーマップ
パウリフィーチャーマップ(PFM)は、任意のパウリゲートを使用するよう ZFM と ZZFM を一般化したものです。パウリフィーチャーマップは、前の 2 つのフィーチャーマップと非常に似た形をとります。ベクトル の 個の特徴量を 回繰り返してエンコードすると、
PFM では、 はパウリ展開のユニタリ演算子に一般化されます。ここでは、これまで検討してきたフィーチャーマップのより一般化された形を示します。
ここで はパウリ演算子 です。 は、1 量子ビットゲートが作用する量子ビットの集合を含む、フィーチャーマップによって決定されるすべての量子ビット接続性の集合です。例えば、量子ビット 0 に位相ゲートが、量子ビット 2 と 3 に ゲートが作用するフィーチャーマップの場合、集合 は を含みます。 はその集合のすべての要素を走ります。以前のフィーチャーマップでは、関数 は 1 量子ビットゲートのみか 2 量子ビットゲートのみに関与していました。ここではそれを一般的に定義します。
ドキュメントについては Qiskit の Pauli feature map クラスのドキュメントを参照してください。ZZFM では、演算子 は に制限されています。
上記のユニタリを理解する一つの方法は、物理系の伝播子との類比です。上記のユニタリは、ハミルトニアン に対するユニタリ発展演算子 であり、イジングモデルに類似しています。時間パラメータ がデータ値に置き換えられて発展を駆動します。このユニタリ演算子の展開が PFM 回路を与えます。 のエンタングルメント接続性は、スピン格子内のイジング結合として解釈できます。
パウリ および 演算子がそれらのイジング型相互作用を表す例を考えてみましょう。Qiskit は、1 量子ビットおよび 量子ビットゲートの選択を伴う PFM をインスタンス化するための pauli_feature_map クラスを提供しています。この例では、パウリ文字列 'Y' と 'XX' として渡されます。通常、 は 1 量子ビット相互作用と 2 量子ビット相互作用でそれぞれ 1 または 2 です。エンタングルメントスキームは「線形」であり、量子回路内の隣接する量子ビットのみが結合されます。なお、これは量子コンピュータ上の実際の隣接量子ビットに対応するわけではなく、この量子回路は抽象化レイヤーです。
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit はパウリフィーチャーマップにおいてパウリ回転のスケーリングを制御するパラメータ を提供しています。
のデフォルト値は です。例えば の区間でその値を最適化することで、量子カーネルをデータによりよく合わせることができます。
パウリフィーチャーマップのギャラリー
ここでは、2 量子ビット回路のさまざまなパウリフィーチャーマップを可視化して、可能性の幅をより深く理解します。
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
上記はもちろん、パウリ行列の他の順列や繰り返しを含むよう拡張できます。学習者はそれらのオプションを試してみることをお勧めします。
組み込みフィーチャーマップのレビュー
量子回路へのデータエンコードについて、いくつかのスキームを見てきました。
- 基底エンコード
- 振幅エンコード
- 角度エンコード
- 位相エンコード
- デンスエンコード
これらのエンコードスキームを使って独自のフィーチャーマップを構築する方法を学び、角度エンコードと位相エンコードを活用した 4 つの組み込みフィーチャーマップも見てきました。
- Efficient SU2
- Z フィーチャーマップ
- ZZ フィーチャーマップ
- パウリフィーチャーマップ
これらの組み込みフィーチャーマップは、以下の点でそれぞれ異なっています。
- エンコードされる特徴量の数に対する深さ
- 特定の数の特徴量に必要な量子ビット数
- エンタングルメントの度合い(明らかに他の違いとも関連しています)
以下のコードでは、これら 4 つの組み込みフィーチャーマップを特徴量セットのエンコードに適用し、結果として得られる回路の 2 量子ビット深さをプロットします。2 量子ビットのエラー率は 1 量子ビットゲートのエラー率よりもはるかに高いため、2 量子ビットゲートの深さに最も関心を持つのは合理的です。以下のコードでは、回路を分解してから count_ops() を使用することで回路内のすべてのゲートのカウントを取得します。ここで関心のある 2 量子ビットゲートは 'cx' ゲートです。
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
一般に、パウリフィーチャーマップと ZZ フィーチャーマップは、efficient_su2 や Z フィーチャーマップよりも回路深さが大きく、2 量子ビットゲートの数も多くなります。
Qiskit に組み込まれたフィーチャーマップは広く適用可能であるため、特に学習段階では独自のものを設計する必要はないことが多いです。しかし、量子機械学習の専門家は、次の 2 つの複雑な課題に取り組む中で、独自のフィーチャーマッピングの設計というテーマに再び向き合うことになるでしょう。
-
現代のハードウェア:ノイズの存在と誤り訂正コードの大きなオーバーヘッドにより、現在のアプリケーションではハードウェア効率や 2 量子ビットゲート深さの最小化などを考慮する必要があります。
-
対象問題に適した写像:例えば
zz_feature_mapが古典的にシミュレートが困難であり、興味深いと言うことと、zz_feature_mapが あなたの 機械学習タスクやデータセットに理想的に適合しているということは、全く別の話です。異なる種類のデータに対する異なるパラメータ化量子回路の性能は、活発に研究されている分野です。
ハードウェア効率についての補足で締めくくります。
ハードウェア効率の高いフィーチャーマッピング
ハードウェア効率の高いフィーチャーマッピングとは、計算におけるノイズやエラーを低減するために、実際の量子コンピュータの制約を考慮したフィーチャーマッピングです。近期量子コンピュータで量子回路を実行する際、ハードウェア固有のノイズを緩和するための多くの戦略があります。ハードウェア効率のための主な戦略の 1 つは、量子回路の深さを最小化することです。これにより、ノイズやデコヒーレンスが計算を損なう時間が短くなります。量子回路の深さとは、計算全体を完了するために必要な時間整合ゲートステップの数です(回路最適化後)[5]。抽象的な論理回路の深さは、実際の量子コンピュータ向けにトランスパイルされた後の深さよりもはるかに低くなる場合があることに注意してください。
トランスパイルとは、量子回路をハードウェアの制約を考慮しながら高レベルの抽象から実際の量子コンピュータで実行可能な形式に変換するプロセスです。量子コンピュータにはネイティブな 1 量子ビットゲートおよび 2 量子ビットゲートのセットがあります。つまり、Qiskit コード内のすべてのゲートはネイティブハードウェアゲートのセットにトランスパイルされる必要があります。例えば、2023 年に完成した Heron r1 プロセッサを搭載した QPU である ibm_torino では、ネイティブゲートまたは基底ゲートは {CZ, ID, RZ, SX, X} です。これらはそれぞれ、2 量子ビット制御-Z ゲート、および恒等演算、-回転、NOT の平方根、NOT と呼ばれる 1 量子ビットゲートであり、普遍的なゲートセットを提供します。多量子ビットゲートを等価なサブ回路として実装する場合、ハードウェアで利用可能な物理的な 2 量子ビット ゲートと他の 1 量子ビットゲートが必要です。さらに、物理的に結合されていない量子ビットペアに 2 量子ビットゲートを適用するには、量子ビット状態を量子ビット間で移動させて結合を可能にするための SWAP ゲートが追加され、回路の不可避な延長が生じます。optimization 引数を 0 から最高レベルの 3 まで設定することができます。より細かい制御とカスタマイズ性のために、トランスパイラパイプラインは Qiskit Pass Manager で管理できます。トランスパイルの詳細については Qiskit トランスパイラドキュメント を参照してください。
Havlicek et al. 2019 [2] では、著者らがハードウェア効率を実現する方法の 1 つとして、第 2 次展開である フィーチャーマップの使用があります(上記の「 フィーチャーマップ」セクションを参照)。 次展開は 量子ビットゲートを持ちます。IBM® の量子コンピュータは のネイティブ 量子ビットゲートを持たないため、実装するにはハードウェアで利用可能な 2 量子ビット CNOT ゲートへの分解が必要です。著者らが深さを最小化する 2 つ目の方法は、アーキテクチャの結合に直接対応する 結合トポロジーを選択することです。さらに彼らが取り組む最適化として、適切に接続された高性能なハードウェアサブ回路をターゲットにすることがあります。その他に考慮すべき事項として、フィーチャーマップの繰り返し数を最小化すること、すべての量子ビットをエンタングルする「全結合」スキームの代わりにカスタマイズされた低深さまたは「線形」エンタングルスキームを選択することが挙げられます。

上図は、物理量子ビットとハードウェア結合をそれぞれノードとエッジで表したネットワークを示しています。ibm_torino の結合マップとパフォーマンスが、可能なすべての 2 量子ビット CZ 結合ゲートとともに示されています。量子ビットは T1 緩和時間(マイクロ秒単位)に基づくスケールで色分けされており、T1 時間が長いほど良好で、明るい色で示されています。結合エッジは CZ エラーによって色分けされており、暗い色ほど良好です。ハードウェア仕様の情報はハードウェアバックエンドの設定スキーマ IBMQBackend.configuration() でアクセスできます。
参考文献
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()