例とアプリケーション
このレッスンでは、変分アルゴリズムのいくつかの例とその適用方法を探ります。
- カスタム変分アルゴリズムの書き方
- 変分アルゴリズムを用いて最小固有値を求める方法
- 変分アルゴリズムを活用してアプリケーションのユースケースを解く方法
なお、Qiskitパターンフレームワークはここで紹介するすべての問題に適用できます。ただし、繰り返しを避けるため、実際のハードウェアで実行する1つの例のみフレームワークのステップを明示的に説明します。
問題の定義
以下のオブザーバブルの固有値を変分アルゴリズムで求めたいとします。
このオブザーバブルは次の固有値を持ちます。
および固有状態:
# Added by doQumentation — required packages for this notebook
!pip install -q numpy qiskit qiskit-ibm-runtime rustworkx scipy
from qiskit.quantum_info import SparsePauliOp
observable_1 = SparsePauliOp.from_list([("II", 2), ("XX", -2), ("YY", 3), ("ZZ", -3)])
カスタムVQE
まず、 の最小固有値を求めるためにVQEインスタンスを手動で構築する方法を探ります。これにより、このコース全体で取り上げたさまざまな技法を組み合わせます。
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
return cost
from qiskit.circuit.library.n_local import n_local
from qiskit import QuantumCircuit
import numpy as np
reference_circuit = QuantumCircuit(2)
reference_circuit.x(0)
variational_form = n_local(
num_qubits=2,
rotation_blocks=["rz", "ry"],
entanglement_blocks="cx",
entanglement="linear",
reps=1,
)
raw_ansatz = reference_circuit.compose(variational_form)
raw_ansatz.decompose().draw("mpl")
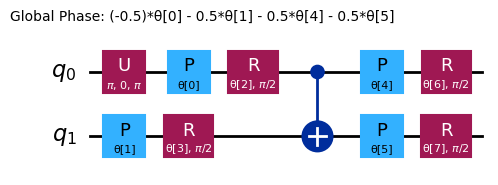
まずローカルシミュレーターでデバッグを開始します。
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
次に初期パラメーターセットを設定します。
x0 = np.ones(raw_ansatz.num_parameters)
print(x0)
[1. 1. 1. 1. 1. 1. 1. 1.]
このコスト関数を最小化して最適パラメーターを計算できます。
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe,
x0,
args=(raw_ansatz, observable_1, estimator),
method="COBYLA",
options={"maxiter": 1000, "disp": True},
)
end_time = time.time()
execution_time = end_time - start_time
Return from COBYLA because the trust region radius reaches its lower bound.
Number of function values = 103 Least value of F = -5.999999998357189
The corresponding X is:
[2.27483579e+00 8.37593091e-01 1.57080508e+00 5.82932911e-06
2.49973063e+00 6.41884255e-01 6.33686904e-01 6.33688223e-01]
result
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -5.999999998357189
x: [ 2.275e+00 8.376e-01 1.571e+00 5.829e-06 2.500e+00
6.419e-01 6.337e-01 6.337e-01]
nfev: 103
maxcv: 0.0
このトイプロブレムは2 Qubitのみを使用しているため、NumPyの線形代数固有値ソルバーを使って検証できます。
from numpy.linalg import eigvalsh
solution_eigenvalue = min(eigvalsh(observable_1.to_matrix()))
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((result.fun - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Number of iterations: 103
Time (s): 0.4394676685333252
Percent error: 2.74e-08
ご覧のとおり、結果は理想値に非常に近い値になっています。
速度と精度の改善に向けた実験
参照状態の追加
前の例では参照演算子 を使用していませんでした。ここで、理想的な固有状態 をどのように得られるか考えてみましょう。次のCircuitを考えます。
from qiskit import QuantumCircuit
ideal_qc = QuantumCircuit(2)
ideal_qc.h(0)
ideal_qc.cx(0, 1)
ideal_qc.draw("mpl")

このCircuitが目的の状態を与えることを簡単に確認できます。
from qiskit.quantum_info import Statevector
Statevector(ideal_qc)
Statevector([0.70710678+0.j, 0. +0.j, 0. +0.j,
0.70710678+0.j],
dims=(2, 2))
解の状態を準備するCircuitの形を確認したので、アダマールGateを参照Circuitとして使用することが合理的だと考えられます。その結果、完全なansatzは次のようになります。
reference = QuantumCircuit(2)
reference.h(0)
reference.cx(0, 1)
# Include barrier to separate reference from variational form
reference.barrier()
ref_ansatz = variational_form.decompose().compose(reference, front=True)
ref_ansatz.draw("mpl")
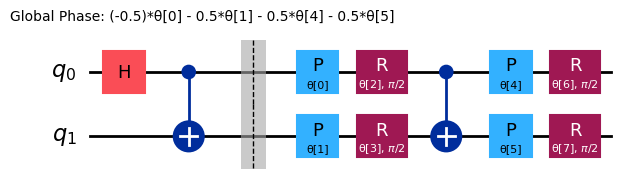
この新しいCircuitでは、すべてのパラメーターを に設定することで理想的な解に到達できるため、参照Circuitの選択が適切であることが確認されます。
では、コスト関数の評価回数、オプティマイザーの反復回数、所要時間を前回の試みと比較してみましょう。
import time
start_time = time.time()
ref_result = minimize(
cost_func_vqe, x0, args=(ref_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
最適パラメーターを使って最小固有値を計算します。
experimental_min_eigenvalue_ref = cost_func_vqe(
ref_result.x, ref_ansatz, observable_1, estimator
)
print(experimental_min_eigenvalue_ref)
-5.999999996759607
print("ADDED REFERENCE STATE:")
print(f"""Number of iterations: {ref_result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((experimental_min_eigenvalue_ref - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
ADDED REFERENCE STATE:
Number of iterations: 127
Time (s): 0.5620882511138916
Percent error: 5.40e-08
お使いのシステムによっては、この非常に小規模な例では速度や精度の改善につながらない場合もあります。重要な点は、問題のスケールが大きくなるにつれて、物理的に動機付けられた参照状態から始めることが速度と精度の向上においてますます重要になるということです。
初期点の変更
参照状態を追加した効果を確認したので、次は初期点 を変えた場合に何が起きるかを見ていきます。特に と を使用します。
参照状態を導入したときに説明したように、すべてのパラメーターが のときに理想的な解が見つかるため、最初の初期点ではより少ない評価回数で収束するはずです。
import time
start_time = time.time()
x0 = [0, 0, 0, 0, 6, 0, 0, 0]
x0_1_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 1:")
print(f"""Number of iterations: {x0_1_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 1:
Number of iterations: 108
Time (s): 0.4492197036743164
初期点を に調整します。
import time
start_time = time.time()
x0 = 6 * np.ones(raw_ansatz.num_parameters)
x0_2_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 2:")
print(f"""Number of iterations: {x0_2_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 2:
Number of iterations: 107
Time (s): 0.40889453887939453
さまざまな初期点を試すことで、より少ない関数評価回数でより速く収束できる可能性があります。
異なるオプティマイザーを試す
オプティマイザーは SciPy の minimize の method 引数を使って変更できます。利用可能なオプションの一覧はこちらで確認できます。これまでは制約付き最小化器(COBYLA)を使用していましたが、ここでは制約なし最小化器(BFGS)に切り替える例を見てみましょう。
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="BFGS"
)
end_time = time.time()
execution_time = end_time - start_time
print("CHANGED TO BFGS OPTIMIZER:")
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
CHANGED TO BFGS OPTIMIZER:
Number of iterations: 117
Time (s): 0.31656408309936523
VQD の例
ここでは Qiskit パターンズフレームワークを明示的に実装します。
ステップ 1: 古典的な入力を量子問題にマッピングする
今回は、観測量の最小固有値だけを求めるのではなく、 つすべての固有値を求めます()。
VQD のコスト関数は以下の通りです:
これは特に重要な点で、VQD オブジェクトを定義する際に、ベクトル (この場合は )を引数として渡す必要があります。
また、Qiskit の VQD 実装では、前のノートブックで説明した有効観測量を用いる代わりに、忠実度 が ComputeUncompute アルゴリズムによって直接計算されます。このアルゴリズムは Sampler プリミティブを活用して、Circuit
において が得られる確率をサンプリングします。これが有効なのは、その確率が以下の通りだからです:
ansatz = n_local(
num_qubits=2,
rotation_blocks=["ry", "rz"],
entanglement_blocks="cz",
# entanglement="linear",
reps=1,
)
ansatz.decompose().draw("mpl")
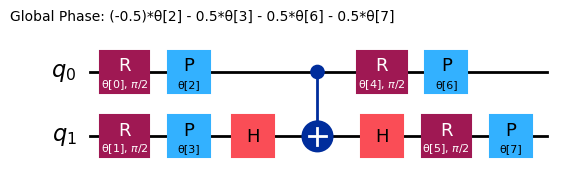
次の観測量を考えてみましょう:
この観測量は以下の固有値を持ちます:
そして固有状態は:
from qiskit.quantum_info import SparsePauliOp
observable_2 = SparsePauliOp.from_list([("II", 2), ("XX", -3), ("YY", 2), ("ZZ", -4)])
次に、重なりペナルティを計算する関数を定義します。これは依然として問題を量子 Circuit にマッピングする部分に含まれますが、前のレッスンで説明したように、この関数は現在の変分 Circuit と、以前に得られた低エネルギー・低コスト状態に対して最適化された Circuit との重なりを計算します。生成される新しい Circuit も、実機で実行するために Transpile する必要があります。この関数はシミュレーターで使用するものとして既に紹介しましたが、ここでは実際の Backend を使用する場合の Transpile と最適化も考慮する必要があります。そのため if realbackend == 1 に関連する行が含まれています。これはステップ 2 の内容が一部混在していますが、後でステップ 2 を明示的に呼び出す際に改めて説明します。
import numpy as np
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
def calculate_overlaps(
ansatz, prev_circuits, parameters, sampler, realbackend, backend
):
def create_fidelity_circuit(circuit_1, circuit_2):
if len(circuit_1.clbits) > 0:
circuit_1.remove_final_measurements()
if len(circuit_2.clbits) > 0:
circuit_2.remove_final_measurements()
circuit = circuit_1.compose(circuit_2.inverse())
circuit.measure_all()
return circuit
overlaps = []
for prev_circuit in prev_circuits:
fidelity_circuit = create_fidelity_circuit(ansatz, prev_circuit)
if realbackend == 1:
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
fidelity_circuit = pm.run(fidelity_circuit)
sampler_job = sampler.run([(fidelity_circuit, parameters)])
meas_data = sampler_job.result()[0].data.meas
counts_0 = meas_data.get_int_counts().get(0, 0)
shots = meas_data.num_shots
overlap = counts_0 / shots
overlaps.append(overlap)
return np.array(overlaps)
次に VQD のコスト関数を追加します。前のレッスンと比較して、実機を使用する際の Transpile に対応するため、2 つの追加引数(realbackend と backend)が加わっています。
def cost_func_vqd(
parameters,
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
hamiltonian,
realbackend,
backend,
):
estimator_job = estimator.run([(ansatz, hamiltonian, [parameters])])
total_cost = 0
if step > 1:
overlaps = calculate_overlaps(
ansatz, prev_states, parameters, sampler, realbackend, backend
)
total_cost = np.sum(
[np.real(betas[state] * overlap) for state, overlap in enumerate(overlaps)]
)
estimator_result = estimator_job.result()[0]
value = estimator_result.data.evs[0] + total_cost
return value
ここでも、まずシミュレーターを使ってデバッグを行い、その後に実機へと移行します。
from qiskit.primitives import StatevectorSampler
from qiskit.primitives import StatevectorEstimator
sampler = StatevectorSampler(default_shots=4092)
estimator = StatevectorEstimator()
次に、計算したい状態の数、ペナルティ、および初期パラメーター x0 を設定します。
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = [50, 60, 40]
x0 = np.ones(8)
それでは、シミュレーターを使ってアルゴリズムをテストしてみましょう:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"maxiter": 200, "tol": 0.000001},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.9999999999996
x: [ 1.571e+00 1.571e+00 2.519e+00 2.100e+00 1.242e+00
6.935e-01 2.298e+00 1.991e+00]
nfev: 151
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 3.698974255258432
x: [ 1.269e+00 1.109e+00 1.080e+00 1.200e+00 1.094e+00
1.163e+00 9.752e-01 9.519e-01]
nfev: 103
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 4.731320121938101
x: [ 1.533e+00 2.451e+00 2.526e+00 2.406e+00 1.968e+00
2.105e+00 8.537e-01 8.442e-01]
nfev: 110
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 7.008239313655201
x: [ 4.150e+00 2.120e+00 3.495e+00 7.262e-01 1.953e+00
-1.982e-01 3.263e-01 2.563e+00]
nfev: 126
maxcv: 0.0
eigenvalues
[np.float64(-6.9999999999996),
np.float64(3.698974255258432),
np.float64(4.731320121938101),
np.float64(7.008239313655201)]
これらの結果は、近似誤差と全体位相を除いて期待値にかなり近い値です。古典的オプティマイザーの許容誤差(tolerance)や状態ベクトルの重なりに対するペナルティを調整することで、より精度の高い値を得ることができます。
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 5.71e-14
Percent error: 2.33e-01
Percent error: 5.37e-02
Percent error: 1.18e-03
ベータ値の変更
前のレッスンで述べたように、 の値は固有値間の差よりも大きくする必要があります。 を用いて、その条件を満たさない場合に何が起こるかを見てみましょう。
固有値は以下の通りです。
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = np.ones(3)
x0 = np.zeros(8)
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.01, "maxiter": 200},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.999916534745094
x: [ 1.568e+00 -1.569e+00 1.385e-01 1.398e-01 -7.972e-01
7.835e-01 -2.375e-01 4.539e-02]
nfev: 125
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -1.515139929812874
x: [-5.317e-04 -2.514e-03 1.016e+00 9.998e-01 3.890e-04
1.772e-04 1.568e-04 8.497e-04]
nfev: 35
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.509948114293115
x: [-3.796e-03 8.853e-03 3.015e-04 9.997e-01 6.271e-04
-2.554e-03 1.017e-04 2.766e-04]
nfev: 37
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 0.4914672235935682
x: [-7.178e-03 -8.652e-03 1.125e+00 -5.428e-02 -1.586e-03
2.031e-03 -3.462e-03 5.734e-03]
nfev: 35
maxcv: 0.0
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 1.19e-05
Percent error: 1.51e+00
Percent error: 1.10e+00
Percent error: 9.30e-01
今回は、オプティマイザーがすべての固有状態の解候補として同じ状態 を返しています。これは明らかに誤りです。これは、ベータ値が小さすぎて、後続のコスト関数において最小固有状態にペナルティを与えられなかったために発生します。そのため、アルゴリズムの後続のイテレーションにおける実効的な探索空間から除外されず、常に最良の解として選ばれてしまいます。
の値をいろいろ試して、固有値間の差よりも大きな値に設定することを推奨します。
ステップ 2:量子実行のための問題の最適化
実機ハードウェアで実行するには、選択した量子コンピュータ向けに量子 Circuit を最適化する必要があります。ここでは、最も空いている Backend を使用します。
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or use a specific backend
# backend = service.backend("ibm_brisbane")
print(backend)
<IBMBackend('ibm_brisbane')>
プリセットパスマネージャーと最適化レベル 3 を使用して Circuit をトランスパイルします。
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = observable_2.apply_layout(layout=isa_ansatz.layout)
ステップ 3:Qiskit プリミティブを使った実行
ベータ値を十分に大きい値にリセットした上で、実際の量子ハードウェアで計算を実行できます。
# Estimated compute resource usage: 25 minutes.
# Benchmarked at 24 min, 30 sec on an Eagle r3 processor on 5-30-24
k = 2
betas = [30, 50, 80]
x0 = np.zeros(8)
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=10_000)
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(isa_ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"maxiter": 200},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
ステップ 4:後処理と古典的な形式での結果の返却
出力の構造は、前のレッスンや例で説明したものと同様です。しかし、上記の結果には問題点があり、励起状態を扱う際の注意点を示唆しています。この学習例で使用する計算時間を抑えるため、古典オプティマイザーの最大イテレーション数を 200 に設定しましたが、これは少なすぎた可能性があります。先ほどシミュレーターで行った計算では、200 イテレーションで収束しませんでした。今回は収束しましたが、どの程度の許容誤差で収束したのでしょうか?COBYLA に対して収束の判定基準となる許容誤差を指定していませんでした。関数値を確認し、以前の実行結果と比較すると、COBYLA は必要な精度に十分近づくには至っていなかったことがわかります。
もう一つの問題があります。第一励起状態のエネルギーが基底状態のエネルギーよりも低く見えることです!これがどのように起こりうるか考えてみてください。ヒント:今述べた収束点と関係しています。この動作については、VQD を H2 分子に適用した後で詳しく説明します。
量子化学:基底状態と励起エネルギーのソルバー
私たちの目的は、エネルギーを表すオブザーバブル(ハミルトニアン )の期待値を最小化することです。
from qiskit.quantum_info import SparsePauliOp
from qiskit.circuit.library import efficient_su2
H2_op = SparsePauliOp.from_list(
[
("II", -1.052373245772859),
("IZ", 0.39793742484318045),
("ZI", -0.39793742484318045),
("ZZ", -0.01128010425623538),
("XX", 0.18093119978423156),
]
)
chem_ansatz = efficient_su2(H2_op.num_qubits)
chem_ansatz.decompose().draw("mpl")
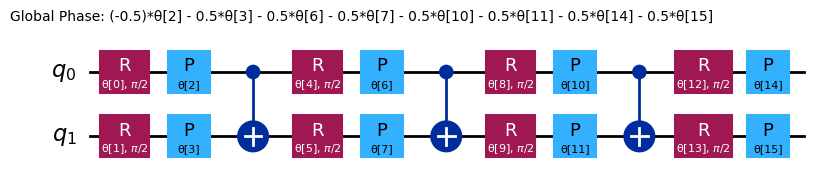
from qiskit import QuantumCircuit
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
次に、初期パラメーターのセットを設定します。
import numpy as np
x0 = np.ones(chem_ansatz.num_parameters)
このコスト関数を最小化して最適なパラメーターを求めることができます。まずはローカルシミュレーターを使ってコードを確認しましょう。
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(chem_ansatz, H2_op, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
result
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.857275029048451
x: [ 7.326e-01 1.354e+00 ... 1.040e+00 1.508e+00]
nfev: 242
maxcv: 0.0
コスト関数の最小値(-1.857...)は、H2 分子の基底状態エネルギー(単位:ハートリー)です。
励起状態
VQD を活用して、 の合計状態数(基底状態と第一励起状態)を求めることもできます。
from qiskit.quantum_info import SparsePauliOp
import numpy as np
k = 2
betas = [33, 33]
# x0 = np.zeros(ansatz.num_parameters)
x0 = [
1.164e00,
-2.438e-01,
9.358e-04,
6.745e-02,
1.990e00,
9.810e-02,
6.154e-01,
5.454e-01,
]
重なり積分の計算を追加します。
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
H2_op,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 2000},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.8572671093941977
x: [ 1.164e+00 -2.437e-01 2.118e-03 6.448e-02 1.990e+00
9.870e-02 6.167e-01 5.476e-01]
nfev: 58
maxcv: 0.0
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.0322873777662176
x: [ 3.205e+00 1.502e+00 1.699e+00 -1.107e-02 3.086e+00
1.530e+00 4.445e-02 7.013e-02]
nfev: 99
maxcv: 0.0
eigenvalues
[-1.8572671093941977, -1.0322873777662176]
実機ハードウェアと最後の注意事項
実機で実行するには、使用する量子コンピュータ向けに量子回路を最適化する必要があります。ここでは、最も空いている Backend を使用します。
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
トランスパイルにはプリセットパスマネージャーを使用し、最適化レベル 3 で回路を最大限に最適化します。
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = H2_op.apply_layout(layout=isa_ansatz.layout)
VQD は反復処理が非常に多いため、すべてのステップを Runtime セッション内で実行します。これにより、ジョブはセッション開始時に一度だけキューに登録され、パラメーターの更新ごとに再登録されることはありません。コスト関数や Estimator の構文に変更はありません。
x0 = [
1.306e00,
-2.284e-01,
6.913e-02,
-2.530e-02,
1.849e00,
7.433e-02,
6.366e-01,
5.600e-01,
]
# Estimated hardware usage: 20 min benchmarked on an Eagle r3 processor on 5-30-24
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=4096)
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(
isa_ansatz.assign_parameters(real_prev_opt_parameters)
)
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 300},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
得られた基底状態エネルギー(-1.83 ハートリー)は正確な値(-1.85 ハートリー)からそれほど離れていません。しかし、励起状態エネルギーはかなりずれています。これは本レッスンで以前見た誤った挙動と同様です。励起状態として報告されたエネルギーが基底状態のそれとほぼ同じになっています。前の例では、励起状態エネルギーが報告された基底状態エネルギーよりも 低い という結果すら見られました。
変分計算で真の基底状態エネルギーより低いエネルギーが得られることはあり得ません。前の例において基底状態エネルギーが真の値に近くなかったため、矛盾は生じていませんでした。今回の場合、基底状態エネルギーは正確な値にかなり近かったにもかかわらず、励起状態エネルギーが不自然にも基底状態のエネルギーに近い値になっています。
この現象を理解するために、励起状態を求める方法を思い出してください。変分状態が基底状態と直交することを要求することで励起状態を求めています(重なり回路とペナルティ項を使用)。正確な基底状態エネルギーが得られなかった場合(数パーセントの誤差がある場合)、正確な基底状態ベクトルも得られません。そのため、励起状態を最初に求めた状態と直交させようとしても、真の基底状態との直交性を課しているのではなく、その近似値(場合によっては精度の低い近似値)との直交性を課しているにすぎません。したがって、励起状態は真の基底状態と直交するよう強制されず、結果として励起状態のエネルギー推定値が基底状態エネルギーに非常に近い値となったのです。
これは VQD において常に懸念される問題です。しかし原則として、古典的オプティマイザーの最大反復回数を増やし、許容誤差を小さく設定し、さらに真の基底状態を繰り返し外している場合には別の ansatz を試すことで改善できます。また、重なりペナルティ(betas)の調整も必要になる場合があります。しかしこれは本質的に別の問題です。重なりペナルティがどれほど適切でも、真の基底状態の良い推定値が得られていなければ、重なり回路を使って真の基底状態から離れた状態を維持することはできません。
最適化:Max-Cut
最大カット(Max-Cut)問題は、グラフの頂点を二つの互いに素な集合に分割し、二つの集合間のエッジ数を最大化する組み合わせ最適化問題です。より形式的に述べると、無向グラフ ( は頂点の集合、 はエッジの集合)が与えられたとき、一方の端点が に、もう一方の端点が にあるエッジの数が最大になるように、頂点を二つの互いに素な部分集合 と に分割する問題です。
Max-Cut はクラスタリング、ネットワーク設計、相転移といった様々な問題に応用できます。まず問題グラフを作成します。
import rustworkx as rx
from rustworkx.visualization import mpl_draw
n = 4
G = rx.PyGraph()
G.add_nodes_from(range(n))
# The edge syntax is (start, end, weight)
edges = [(0, 1, 1.0), (0, 2, 1.0), (0, 3, 1.0), (1, 2, 1.0), (2, 3, 1.0)]
G.add_edges_from(edges)
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color="#1192E8"
)

この問題は二値最適化問題として表現できます。グラフのノード数を (今回は )とし、 の各ノード に対して二値変数 を導入します。この変数は、ノード が「グループ 1」に属する場合は 、「グループ 0」に属する場合は をとります。また、隣接行列 の要素 を とし、ノード からノード へのエッジの重みを表します。グラフは無向なので が成り立ちます。この設定のもと、次のコスト関数を最大化する問題として定式化できます。
この問題を量子コンピュータで解くために、コスト関数をオブザーバブルの期待値として表現します。ただし、Qiskit がネイティブに扱うオブザーバブルはパウリ演算子で構成されており、固有値は と ではなく と をとります。そのため、次の変数変換を行います。
ここで とします。隣接行列 を使うと全エッジの重みに簡単にアクセスでき、コスト関数の導出に役立ちます。
これにより次のことが導かれます。
したがって、最大化すべき新しいコスト関数は次のようになります。
また、量子コンピュータは最大値ではなく最小値(通常は最低エネルギー)を見つけようとするため、 を最大化するのではなく、次の式を最小化します。
変数が と の値をとるコスト関数を最小化する問題が得られたので、パウリ との対応付けを次のように行います。
つまり、変数 は qubit に作用する Gate に対応します。さらに:
したがって、考えるべきオブザーバブルは次のようになります。
これに後から独立項を加える必要があります。
この演算子は、エッジで結ばれたノード上の Z 演算子を含む項の線形結合です(0 番目の qubit が最も右側にあることに注意):。演算子が構成できれば、QAOA アルゴリズムの ansatz は Qiskit Circuit ライブラリの QAOAAnsatz Circuit を使って簡単に構築できます。
from qiskit.circuit.library import QAOAAnsatz
from qiskit.quantum_info import SparsePauliOp
max_hamiltonian = SparsePauliOp.from_list(
[("IIZZ", 1), ("IZIZ", 1), ("IZZI", 1), ("ZIIZ", 1), ("ZZII", 1)]
)
max_ansatz = QAOAAnsatz(max_hamiltonian, reps=2)
# Draw
max_ansatz.decompose(reps=3).draw("mpl")

# Sum the weights, and divide by 2
offset = -sum(edge[2] for edge in edges) / 2
print(f"""Offset: {offset}""")
Offset: -2.5
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
初期パラメーターをランダムに設定します。
import numpy as np
x0 = 2 * np.pi * np.random.rand(max_ansatz.num_parameters)
print(x0)
[6.0252949 0.58448176 2.15785731 1.13646074]
コスト関数の最小化には任意の古典的オプティマイザーを使用できます。実際の量子システムでは、滑らかでないコスト関数の景観に対応したオプティマイザーが通常より良い結果を出します。ここでは SciPy の minimize 関数を介して COBYLA ルーチン を使用します。
Runtime への呼び出しを繰り返し実行するため、セッションを利用してすべての呼び出しを一つのブロック内で実行します。また、QAOA の解は最小化で得られた最適パラメーターを ansatz Circuit に割り当てたときの出力分布に符号化されています。そのため Sampler プリミティブが必要であり、同じセッションでインスタンス化します。最小化ルーティンを実行します。
result = minimize(
cost_func, x0, args=(max_ansatz, max_hamiltonian, estimator), method="COBYLA"
)
print(result)
message: Optimization terminated successfully.
success: True
status: 1
fun: -2.585287311689236
x: [ 7.332e+00 3.904e-01 2.045e+00 1.028e+00]
nfev: 80
maxcv: 0.0
パラメーター角度のベクトル(x)を ansatz Circuit に代入すると、求めていたグラフの分割結果が得られます。
eigenvalue = cost_func(result.x, max_ansatz, max_hamiltonian, estimator)
print(f"""Eigenvalue: {eigenvalue}""")
print(f"""Max-Cut Objective: {eigenvalue + offset}""")
Eigenvalue: -2.585287311689236
Max-Cut Objective: -5.085287311689235
from qiskit.result import QuasiDistribution
from qiskit.primitives import StatevectorSampler
sampler = StatevectorSampler()
# Assign solution parameters to ansatz
qc = max_ansatz.assign_parameters(result.x)
# Add measurements to our circuit
qc.measure_all()
# Sample ansatz at optimal parameters
# samp_dist = sampler.run(qc).result().quasi_dists[0]
shots = 1024
job = sampler.run([qc], shots=shots)
qc.decompose().draw("mpl")

data_pub = job.result()[0].data
bitstrings = data_pub.meas.get_bitstrings()
counts = data_pub.meas.get_counts()
quasi_dist = QuasiDistribution(
{outcome: freq / shots for outcome, freq in counts.items()}
)
probabilities = quasi_dist
# Close the session since we are now done with it
# session.close()
from qiskit.visualization import plot_distribution
plot_distribution(counts)

binary_string = max(counts.items(), key=lambda kv: kv[1])[0]
x = np.asarray([int(y) for y in reversed(list(binary_string))])
colors = ["r" if x[i] == 0 else "c" for i in range(n)]
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color=colors
)

まとめ
このレッスンでは、以下のことを学びました。
- カスタム変分アルゴリズムの書き方
- 変分アルゴリズムを最小固有値の探索に適用する方法
- 変分アルゴリズムを応用ユースケースの解決に活用する方法
最終レッスンに進んで、アセスメントを受け、バッジを獲得しましょう!