グローバーのアルゴリズム
このQiskit教室モジュールの場合、学生は次のパッケージがインストールされた動作するPython環境を持っている必要があります:
qiskitv2.1.0以降qiskit-ibm-runtimev0.40.1以降qiskit-aerv0.17.0以降qiskit.visualizationnumpypylatexenc
上記のパッケージをセットアップしてインストールするには、Qiskitのインストールガイドを参照してください。 実際の量子コンピュータでジョブを実行するには、学生はIBM Cloudアカウントの設定ガイドの手順に従って、IBM Quantum®でアカウントを設定する必要があります。
このモジュールはテストされ、12秒のQPU時間を使用しました。これは誠実な見積もりです。実際の使用量は異なる場合があります。
# Added by doQumentation — required packages for this notebook
!pip install -q qiskit qiskit-ibm-runtime
# Uncomment and modify this line as needed to install dependencies
#!pip install 'qiskit>=2.1.0' 'qiskit-ibm-runtime>=0.40.1' 'qiskit-aer>=0.17.0' 'numpy' 'pylatexenc'
はじめに
グローバーのアルゴリズムは、構造化されていない検索問題に対処する基礎的な量子アルゴリズムです: 個のアイテムのセットと、任意のアイテムが探しているものであるかどうかをチェックする方法が与えられたとき、目的のアイテムをどれだけ速く見つけることができますか?古典的コンピューティングでは、データがソートされておらず、利用できる構造がない場合、最良のアプローチは各アイテムを1つずつチェックすることであり、クエリの複雑さはになります。平均して、ターゲットを見つける前に約半分のアイテムをチェックする必要があります。
1996年にLov Groverによって導入されたグローバーのアルゴリズムは、量子コンピュータがこの問題をはるかに効率的に解決できる方法を示し、マークされたアイテムを高い確率で見つけるためにステップしか必要としません。これは、古典的方法に対する二次的な高速化を表しており、大規模なデータセットにとって重要です。
アルゴリズムは次の文脈で動作します:
- 問題設定: が欲しいアイテムである場合は1を返し、そうでない場合は0を返す関数があります。この関数は、をクエリすることによってのみデータについて学習できるため、しばしばオラクルまたはブラックボックスと呼ばれます。
- 量子の有用性: この問題の古典的アルゴリズムは平均して回のクエリを必要としますが、グローバーのアルゴリズムは約回のクエリで解を見つけることができ、大きなに対してははるかに高速です。
- 動作の仕組み(高レベル):
- 量子コンピュータはまず、すべての可能なアイテムを一度に表すすべての可能な状態の重ね合わせを作成します。
- 次に、正しい答えの確率を増幅し、他の確率を減少させる一連の量子演算(グローバー反復)を繰り返し適用します。
- 十分な反復の後、量子状態を測定すると、高い確率で正しい答えが得られます。
これは、多くのニュアンスをスキップしたグローバーのアルゴリズムの非常に基本的な図です。より詳細な図については、この論文を参照してください。
グローバーのアルゴリズムについて注意すべきいくつかの点:
- 構造化されていない検索に最適です: 回未満のクエリで問題を解決できる量子アルゴリズムはありません。
- 指数関数的ではなく二次的な高速化のみを提供します。他の量子アルゴリズム(たとえば、因数分解のためのショアのアルゴリズム)とは異なります。
- 暗号システムに対するブルートフォース攻撃を潜在的に高速化するなど、実用的な意味がありますが、高速化はそれ自体でほとんどの最新の暗号化を破るには十分ではありません。
基本的なコンピューティング概念とクエリモデルに精通している学部生にとって、グローバーのアルゴリズムは、量子コンピューティングが特定の問題に対して古典的アプローチをどのように上回ることができるかの明確な例を提供します。改善が「わずか」二次的である場合でも。また、より高度な量子アルゴリズムと量子コンピューティングのより広い可能性を理解するための入り口としても機能します。
振幅増幅は、汎用目的の量子アルゴリズム、またはサブルーチンであり、少数の古典的アルゴリズムに対して二次的な高速化を得るために使用できます。グローバーのアルゴリズムは、構造化されていない検索問題でこの高速化を最初に実証しました。グローバーの検索問題を定式化するには、1つ以上の計算基底状態を見つけたい状態としてマークするオラクル関数と、マークされた状態の振幅を増加させ、その結果残りの状態を抑制する増幅回路が必要です。
ここでは、グローバーオラクルを構築する方法を示し、Qiskit回路ライブラリのGroverOperatorを使用してグローバーの検索インスタンスを簡単にセットアップします。ランタイムSamplerプリミティブにより、グローバー回路のシームレスな実行が可能になります。
理論
バイナリ文字列を単一のバイナリ変数にマッピングする関数が存在するとします。つまり
で定義された1つの例は
で定義された別の例は
が1にマッピングされる引数に対応する量子状態を見つけるタスクがあります。言い換えれば、となるすべてのを見つけます(または解がない場合は、それを報告します)。非解をと呼びます。もちろん、量子状態を使用して量子コンピュータでこれを行うので、これらのバイナリ文字列を状態として表現することが有用です:
量子状態(ディラック)表記法を使用すると、個の可能な状態のセット内の1つ以上の特別な状態を探しています。ここで、は量子ビットの数であり、非解はと表されます。
関数は、オラクルによって提供されると考えることができます: クエリして状態への効果を決定できるブラックボックス。実際には、関数を知っていることが多いですが、実装が非常に複雑な場合があり、つまりのクエリまたはアプリケーションの数を減らすことが重要である可能性があります。あるいは、ある人が別の人によって制御されているオラクルをクエリしているパラダイムを想像することができます。そのため、オラクル関数を知らず、特定の状態に対するそのアクションのみをクエリから知っています。
これは「構造化されていない検索問題」であり、検索を支援するに関する特別なものは何もないという意味です。出力はソートされておらず、解がクラスターを形成することは知られていません。紙の電話帳を例えとして考えてください。この構造化されていない検索は、特定の__番号__を探してそれをスキャンするようなもので、アルファベット順の名前のリストを調べるようなものではありません。
単一の解が求められる場合、古典的には、これにはに対して線形なクエリ数が必要です。明らかに、最初の試行で解を見つけるかもしれませんし、最初の回の推測で解を見つけられない場合があり、そのため入力をクエリして解がまったくあるかどうかを確認する必要があります。関数には利用可能な構造がないため、平均して回の推測が必要になります。グローバーのアルゴリズムは、のようにスケールするのクエリまたは計算の数を必要とします。
グローバーのアルゴリズムの回路のスケッチ
グローバーのアルゴリズムの完全な数学的ウォークスルーは、たとえば、IBM Quantum LearningのJohn Watrousによるコース量子アルゴリズムの基礎にあります。簡潔な扱いは、このモジュールの最後の付録に提供されています。しかし今のところ、グローバーのアルゴリズムを実装する量子回路の全体的な構造のみをレビューします。
グローバーのアルゴリズムは、次の段階に分解できます:
- 初期重ね合わせの準備(すべての量子ビットへのアダマールゲートの適用)
- 位相反転でターゲット状態をマークする
- __すべての__量子ビットにアダマールゲートと位相反転が適用される「拡散」段階
- ターゲット状態を測定する確率を最大化するためのマーキングと拡散段階の反復の可能性
- 測定
 多くの場合、マーキングゲートと、 から構成される拡散層は、まとめて「グローバー演算子」と呼ばれます。この図では、グローバー演算子の1回の反復のみが示されています。
多くの場合、マーキングゲートと、 から構成される拡散層は、まとめて「グローバー演算子」と呼ばれます。この図では、グローバー演算子の1回の反復のみが示されています。
アダマールゲートはよく知られており、量子コンピューティング全体で広く使用されています。アダマールゲートは重ね合わせ状態を作成します。具体的には次のように定義されます
他の状態に対する演算は線形性を通じて定義されます。 特に、アダマールゲートの層により、すべての量子ビットがにある初期状態(と表される)から、各量子ビットがまたはのいずれかで測定される確率を持つ状態に移行できます。これにより、古典的コンピューティングとは異なる方法で、すべての可能な状態の空間を調査できます。
アダマールゲートの重要な系特性は、2回目に作用すると、そのような重ね合わせ状態を元に戻すことができることです:
これはすぐに重要になります。
理解度チェック
以下の質問を読み、答えについて考えてから、三角形をクリックして解決策を明らかにしてください。
アダマールゲートの定義から始めて、アダマールゲートの2回目の適用が上記の主張どおりにそのような重ね合わせを元に戻すことを実証してください。
答え:
Xを状態に適用すると、値+1が得られ、状態に適用すると-1が得られます。したがって、50-50の分布がある場合、期待値0が得られます。
ゲートはあまり一般的ではなく、次のように定義されます
最後に、ゲートは次のように定義されます
これの効果は、がであるターゲット状態の符号を反転し、他の状態を影響を受けないままにすることに注意してください。
非常に高い、抽象的なレベルで、回路のステップを次の方法で考えることができます:
- 最初のアダマール層: 量子ビットをすべての可能な状態の重ね合わせに配置します。
- : 前に「-」記号を追加してターゲット状態をマークします。これはすぐに測定確率を変更しませんが、後続のステップでターゲット状態がどのように動作するかを変更します。
- 別のアダマール層: 前のステップで導入された「-」記号は、いくつかの項の間の相対的な符号を変更します。アダマールゲートは、計算状態の1つの混合を1つの計算状態に変え、をに変えるため、この相対的な符号の違いが、測定される状態で役割を果たし始めることができます。
- アダマールゲートの最後の層が適用され、次に測定が行われます。
次のセクションでは、これがどのように機能するかをより詳細に見ていきます。
例
グローバーのアルゴリズムがどのように機能するかをよりよく理解するために、小さな2量子ビットの例を調べてみましょう。これは、量子力学とディラック表記法に焦点を当てていない人にとってはオプションと見なされる可能性があります。しかし、量子コンピュータで実質的に作業することを望む人にとっては、これを強くお勧めします。
これは、回路全体のさまざまな位置でラベル付けされた量子状態を持つ回路図です。2つの量子ビットしかないことに注意してください。つまり、どのような状況下でも測定できる可能性のある4つの状態しかありません: 、、、。
オラクル(、私たちには未知)が状態をマークすると仮定しましょう。オラクルを含む各量子ゲートのセットのアクションを調べて、測定時にどのような可能な状態の分布が出てくるかを見ていきます。
最初に、次のようになります
アダマールゲートの定義を使用すると、次のようになります
これで、オラクルはターゲット状態をマークします:
この状態では、4つの可能な結果すべてが測定される同じ確率を持っていることに注意してください。それらはすべて大きさの重みを持っています。つまり、それぞれが測定されるの確率を持っています。したがって、状態は「-」位相を通じてマークされていますが、これはまだこの状態を測定する確率の増加をもたらしていません。次のアダマールゲートの層を適用し続けます。
同類項をまとめると、次のようになります
これでが以外のすべての状態の符号を反転します:
そして最後に、アダマールゲートの最後の層を適用します:
これらの項を結合して、結果が実際に次のようになることを自分自身で確信する価値があります:
つまり、を測定する確率は100%(ノイズとエラーがない場合)であり、他の状態を測定する確率はゼロです。
この2量子ビットの例は特にクリーンなケースでした。グローバーのアルゴリズムは、常にターゲット状態を測定する100%の確率をもたらすとは限りません。むしろ、ターゲット状態を測定する確率を増幅します。また、グローバー演算子を1回以上繰り返す必要がある場合があります。
次のセクションでは、このアルゴリズムを実際のIBM®量子コンピュータを使用して実践に移します。
幾何学的な描像
上記の2量子ビットの例では、小さなケースで代数がどのように機能するかを示しましたが、グローバーのアルゴリズムをもっと直感的に理解する方法があります: 2次元平面での一連の幾何学的反射として。以下にこの描像を説明します。詳細については、John Watrousのコース量子アルゴリズムの基礎も参照してください。
平面の設定。 初期重ね合わせ状態を2つの成分に分解できます。正しい状態—探している状態—をと呼びます。他のすべての状態をまとめてと呼びます。定義上、とは互いに直交しているため、抽象的な2次元空間で直交軸としてプロットできます。はこれら2つの成分の線形結合であるため、軸から小さな角度の位置にあります—最初は状態のごく一部しか正しい成分にないため、に近い位置にあります。
反射。 必要な重要な数学的事実は、次の形の演算子が
で定義される軸について任意の状態を反射することです。理由を理解するには、2つのケースを考えます: に沿った状態は変化せず、に垂直な状態は符号が反転します。他の状態はこれら2つの成分に分解でき、演算子はそれぞれに対応して作用します—これはまさにについての反射です。
グローバーのアルゴリズムのオラクルと拡散の両ステップが、この幾何学的描像で反射として表現できることがわかります。
オラクルを反射として。 オラクルは状態の符号を反転し、他のすべてをそのままにします。これは軸についての反射と同じです。
拡散を反射として。 拡散演算子も反射であることを理解するのは少し難しいです。拡散演算子は
単体は全ゼロ状態についての反射です。でないすべての状態の符号を反転するからです。これはと書けます。周囲のアダマール層は基底変換を効果的に実行し、反射の軸を変換します。がを一様重ね合わせにマッピングすることを思い出してください。アダマールはそれ自身の逆であるため、完全な式は
となり、これはについての反射です。はに非常に近いため(両方ともほぼに沿っています)、この2番目の反射は状態を出発点からの角度に送ります。
の回転。 これら2つの反射の合成効果は、に向かっての回転です。グローバー演算子の各反復は、状態をさらに回転させます。
最適な反復回数。 目標は状態をにできるだけ近く回転させることです。つまり、合計で約ラジアン(4分の1回転)回転させます。各反復がを寄与する場合、最適な反復回数は
を満たします。状態の中に単一の解がある場合、初期角度は(大きなに対して)です。代入すると、
これが有名な高速化の由来です: 古典的な検索が必要とする回のチェックではなく、ターゲットに到達するために回の反復しか必要としません。
より一般的に、総状態の中に個の解状態がある場合、最適な反復回数は
反復を多くしすぎると、を過ぎて回転し、ターゲット状態を見つける確率が再び低下し始めることに注意してください。適切な反復回数を見つけることは重要ですが、ノイズの多い量子ハードウェアでは実験的に最適な数がこの理想的な式と異なる場合があります。
グローバーのアルゴリズムはなぜ有用か?
この時点で、疑問に思うかもしれません: ターゲット状態をマークするオラクルを構築しましたが、構築するにはターゲット状態を知る必要がありました。では、実際に何を検索しているのでしょうか?
これは正当な質問であり、いくつかの良い答えがあります。
-
クエリモデルは理論的なツールです。 計算のクエリモデルは、直接実用的になるように設計されたことはありません。その目的は、問題を2つの部分に分離することで、アルゴリズムの複雑さを分析するクリーンな方法を提供することです: オラクルと、その他すべて。検証が無料の場合、検索はどれほど難しいか?クエリの数は入力のサイズとともにどのようにスケールするか?実際のシステムがまったくこの方法で動作しなくても、これらは有用な質問です。
-
2者間アクティビティとして考えることもできます: ある人がターゲット状態を知ってオラクルを構築し、もう一方の人の仕事は内側を覗かずにブラックボックスとしてオラクルを使用して答えを見つけることです。以下のアクティビティ2では、パートナーとまさにこれを行います。
-
振幅増幅は広く有用なサブルーチンです。 この最初のデモンストレーションが循環的に見えても、基礎となるメカニズム—振幅増幅と呼ばれる—は量子コンピューティングで何度も繰り返し現れます。ここで実際に構築しているのは、より複雑な多くの量子アルゴリズムのサブルーチンとして現れるツールの直感です。
-
答えを知らなくてもオラクルを構築できる問題があります。 重要な洞察は、解を見つけることは非常に難しいが、与えられた解が正しいことを確認することは非常に簡単であるという問題のクラス全体が存在することです。因数分解はその一例です: 2つの大きな素数の積が与えられた場合、それらの素数が何であるかを決定することは非常に困難ですが、一度持てばそれらを掛け合わせて検証するのは簡単です。(因数分解に関してはグローバーよりも優れたアルゴリズムがあります—ショアのアルゴリズムを参照—しかし、これはこの特性を持つ唯一の問題からはほど遠いです。)数独、制約充足問題、さらには古典的なゲームのマインスイーパーも、解くのが難しいが確認するのが簡単な問題です。
これが関係する理由は?それは、解が満たすべきすべての条件と要件を知ることができ、それらの要件をオラクルとして機能する量子回路にエンコードできることを意味します—解自体を知らなくても。グローバーのアルゴリズムがそれを見つけてくれます。
これらのアイデアを念頭に置いて、いくつかの例を調べてみましょう。解状態が明確に指定されている例から始めて、アルゴリズムのロジックに従うことができるようにします。次に、2者間アクティビティに移り、最後に、答えの知識ではなく問題の制約からオラクルが構築される例に移ります。
一般的なインポートとアプローチ
いくつかの必要なパッケージをインポートすることから始めます。
# Built-in modules
import math
# Imports from Qiskit
from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister
from qiskit.circuit.library import grover_operator, MCMTGate, ZGate
from qiskit.visualization import plot_distribution
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
このチュートリアルおよび他のチュートリアル全体で、「Qiskitパターン」として知られる量子コンピューティングのフレームワークを使用します。これは、ワークフローを次のステップに分解します:
- ステップ1: 古典的入力を量子問題にマッピングする
- ステップ2: 量子実行のために問題を最適化する
- ステップ3: Qiskit Runtimeプリミティブを使用して実行する
- ステップ4: 後処理と古典的分析
一般的にこれらのステップに従いますが、常に明示的にラベル付けするとは限りません。
アクティビティ1: 単一の指定されたターゲット状態を見つける
ステップ1: 古典的入力を量子問題にマッピングする
位相クエリゲートは、解状態に全体的な位相(-1)を配置し、非解状態を影響を受けないままにする必要があります。これを言う別の方法は、グローバーのアルゴリズムには、1つ以上のマークされた計算基底状態を指定するオラクルが必要であり、「マークされた」とは位相-1を持つ状態を意味します。これは、制御Zゲート、または量子ビット上のその複数制御の一般化を使用して行われます。これがどのように機能するかを確認するために、ビット文字列{110}の特定の例を考えてみましょう。状態に作用し、の場合に位相を適用する回路が欲しいです(Qiskitの表記法のため、バイナリ文字列の順序を反転しました。これは、最下位(多くの場合0)量子ビットを右側に配置します)。
したがって、次を達成する回路が必要です
複数制御複数ターゲットゲート(MCMTGate)を使用して、すべての量子ビットによって制御されるZゲートを適用できます(すべての量子ビットが状態にある場合に位相を反転します)。もちろん、目的の状態の量子ビットの一部はである可能性があります。したがって、それらの量子ビットに対して、最初にXゲートを適用し、次に複数制御Zゲートを実行し、次に別のXゲートを適用して変更を元に戻す必要があります。MCMTGateは次のようになります:
mcmt_ex = QuantumCircuit(3)
mcmt_ex.compose(MCMTGate(ZGate(), 3 - 1, 1), inplace=True)
mcmt_ex.draw(output="mpl", style="iqp")

多くの量子ビットが制御プロセスに関与している可能性がある(ここでは3つの量子ビットが関与しています)が、単一の量子ビットがターゲットとして示されていないことに注意してください。これは、全体の状態が全体的な「-」符号(位相反転)を取得するためです。ゲートはすべての量子ビットに同等に影響を与えます。これは、単一の制御量子ビットと単一のターゲット量子ビットを持つCXゲートのような、他の多くの複数量子ビットゲートとは異なります。
次のコードでは、上記で説明したことを実行する位相クエリゲート(またはオラクル)を定義します: ビット文字列表現を通じて定義された1つ以上の入力基底状態をマークします。MCMTゲートは、複数制御Zゲートを実装するために使用されます。
def grover_oracle(marked_states):
"""Build a Grover oracle for multiple marked states
Here we assume all input marked states have the same number of bits
Parameters:
marked_states (str or list): Marked states of oracle
Returns:
QuantumCircuit: Quantum circuit representing Grover oracle
"""
if not isinstance(marked_states, list):
marked_states = [marked_states]
# Compute the number of qubits in circuit
num_qubits = len(marked_states[0])
qc = QuantumCircuit(num_qubits)
# Mark each target state in the input list
for target in marked_states:
# Flip target bitstring to match Qiskit bit-ordering
rev_target = target[::-1]
# Find the indices of all the '0' elements in bitstring
zero_inds = [
ind for ind in range(num_qubits) if rev_target.startswith("0", ind)
]
# Add a multi-controlled Z-gate with pre- and post-applied X-gates (open-controls)
# where the target bitstring has a '0' entry
qc.x(zero_inds)
qc.compose(MCMTGate(ZGate(), num_qubits - 1, 1), inplace=True)
qc.x(zero_inds)
return qc
今、ターゲットとなる特定の「マークされた」状態を選択し、定義した関数を適用します。どのような種類の回路を作成したかを見てみましょう。
marked_states = ["1110"]
oracle = grover_oracle(marked_states)
oracle.draw(output="mpl", style="iqp")

量子ビット1-3が状態にあり、量子ビット0が最初に状態にある場合、最初のXゲートは量子ビット0をに反転し、すべての量子ビットがになります。これは、MCMTゲートが全体的な符号変化または位相反転を適用することを意味し、望ましいことです。他のケースでは、量子ビット1-3が状態にあるか、量子ビット0が状態に反転され、位相反転は適用されません。この回路は実際に目的の状態、またはビット文字列{1110}をマークすることがわかります。
完全なグローバー演算子は、位相クエリゲート(オラクル)、アダマール層、演算子で構成されています。組み込みのgrover_operatorを使用して、上記で定義したオラクルからこれを構築できます。
grover_op = grover_operator(oracle)
grover_op.decompose(reps=0).draw(output="mpl", style="iqp")
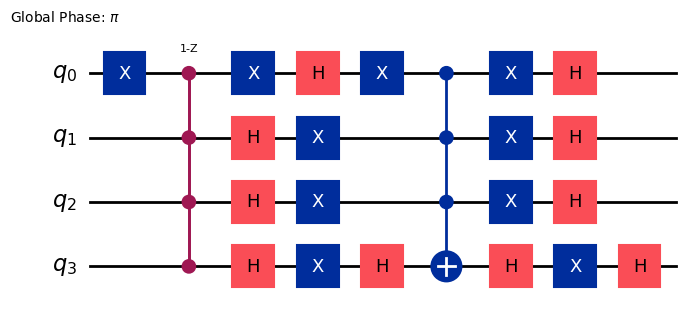
上の幾何学的な描像で説明したように、グローバー演算子を複数回適用する必要がある場合があります。ノイズがない場合にターゲット状態の振幅を最大化するための最適な反復回数は
であり、ここでは解状態の数、は総状態数です。現代のノイズの多い量子コンピュータでは、実験的に最適な反復回数は異なる可能性がありますが—ここではを使用して、この理論的な最適数を計算して使用します。
optimal_num_iterations = math.floor(
math.pi / (4 * math.asin(math.sqrt(len(marked_states) / 2**grover_op.num_qubits)))
)
print(optimal_num_iterations)
3
すべての可能な状態の重ね合わせを作成するための初期アダマールゲートを含む回路を構築し、グローバー演算子を最適回数適用しましょう。
qc = QuantumCircuit(grover_op.num_qubits)
# Create even superposition of all basis states
qc.h(range(grover_op.num_qubits))
# Apply Grover operator the optimal number of times
qc.compose(grover_op.power(optimal_num_iterations), inplace=True)
# Measure all qubits
qc.measure_all()
qc.draw(output="mpl", style="iqp")
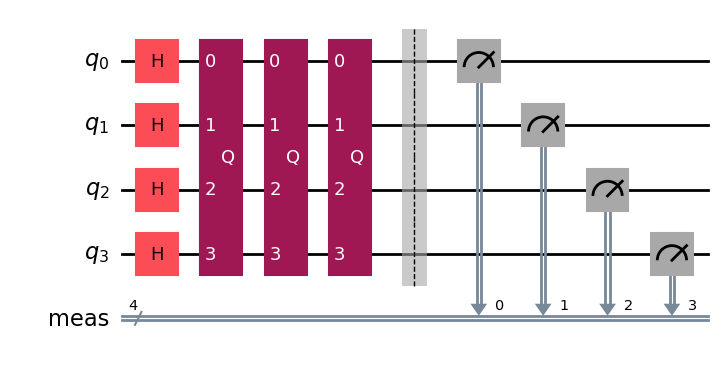
グローバー回路を構築しました!
ステップ2: 量子ハードウェア実行のために問題を最適化する
抽象的な量子回路を定義しましたが、実際に使用したい量子コンピュータにネイティブなゲートの観点からそれを書き直す必要があります。また、量子コンピュータのどの量子ビットを使用するかを指定する必要があります。これらの理由などから、回路をトランスパイルする必要があります。まず、使用したい量子コンピュータを指定しましょう。
最初の使用時に認証情報を保存するための以下のコードがあります。環境に保存した後、ノートブックを共有するときに認証情報が誤って共有されないように、この情報をノートブックから削除してください。詳細については、IBM Cloudアカウントの設定および信頼されていない環境でサービスを初期化するを参照してください。
# To run on hardware, select the backend with the fewest number of jobs in the queue
from qiskit_ibm_runtime import QiskitRuntimeService
# Syntax for first saving your token. Delete these lines after saving your credentials.
# QiskitRuntimeService.save_account(channel='ibm_quantum_platform',
# instance = '<YOUR_IBM_INSTANCE_CRN>', token='<YOUR_API_KEY>', overwrite=True, set_as_default=True)
# service = QiskitRuntimeService(channel='ibm_quantum_platform')
# Load saved credentials
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
backend.name
qiskit_runtime_service._resolve_cloud_instances:WARNING:2025-08-08 14:14:19,931: Default instance not set. Searching all available instances.
'ibm_brisbane'
次に、プリセットパスマネージャーを使用して、選択したバックエンドに対して量子回路を最適化します。
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
circuit_isa = pm.run(qc)
# The transpiled circuit will be very large. Only draw it if you are really curious.
# circuit_isa.draw(output="mpl", idle_wires=False, style="iqp")
この時点で、トランスパイルされた量子回路の深さがかなり大きいことに注目する価値があります。
print("The total depth is ", circuit_isa.depth())
print(
"The depth of two-qubit gates is ",
circuit_isa.depth(lambda instruction: instruction.operation.num_qubits == 2),
)
The total depth is 439
The depth of two-qubit gates is 113
これらは、この単純なケースでもかなり大きな数字です。すべての量子ゲート(特に2量子ビットゲート)はエラーを経験し、ノイズの影響を受けるため、量子ビットが非常に高性能でない場合、100を超える2量子ビットゲートの連続はノイズしかもたらしません。これらがどのように実行されるか見てみましょう。
ステップ3: Qiskitプリミティブを使用して実行する
多くの測定を行い、どの状態が最も可能性が高いかを確認したいと思います。このような振幅増幅は、Sampler Qiskit Runtimeプリミティブでの実行に適したサンプリング問題です。
Qiskit Runtime SamplerV2のrun()メソッドは、プリミティブ統合ブロック(PUB)の反復可能を取ることに注意してください。Samplerの場合、各PUBは(circuit, parameter_values)の形式の反復可能です。ただし、最低限、量子回路のリストを取ります。
# To run on a real quantum computer (this was tested on a Heron r2 processor and
# used 4 sec. of QPU time)
from qiskit_ibm_runtime import SamplerV2 as Sampler
sampler = Sampler(mode=backend)
sampler.options.default_shots = 10_000
result = sampler.run([circuit_isa]).result()
dist = result[0].data.meas.get_counts()
この経験を最大限に活用するには、IBM Quantumから利用可能な実際の量子コンピュータで実験を実行することを強くお勧めします。ただし、QPU時間を使い果たした場合は、以下の行のコメントを外してシミュレータを使用してこのアクティビティを完了できます。
# To run on local simulator:
# from qiskit.primitives import StatevectorSampler as Sampler
# sampler = Sampler()
# result = sampler.run([qc]).result()
# dist = result[0].data.meas.get_counts()
ステップ4: 後処理と結果を目的の古典的形式で返す
これで、サンプリングの結果をヒストグラムにプロットできます。
plot_distribution(dist)
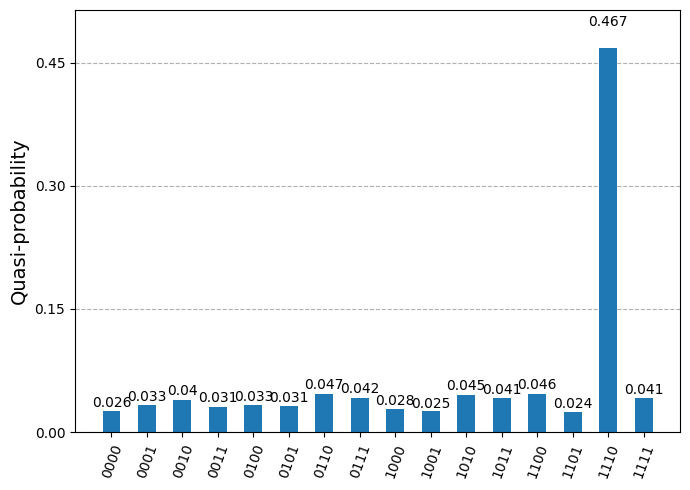
グローバーのアルゴリズムが、他のオプションよりも少なくとも1桁高い確率で、最も高い確率で目的の状態を返したことがわかります。次のアクティビティでは、クエリアルゴリズムの2者間ワークフローとより一致する方法でアルゴリズムを使用します。
理解度チェック
以下の質問を読み、答えについて考えてから、三角形をクリックして解決策を明らかにしてください。
個の可能な状態のセットで単一の解を検索しました。グローバー演算子の最適な反復回数をと決定しました。この最適数は、(a)いくつかの解のいずれか、または(b)より多くの可能な状態の空間での単一の解を検索した場合、増加または減少しますか?
答え:
解の数が全体の解の空間と比較して小さい限り、小さな角度の周りでサイン関数を展開し、次を使用できることを思い出してください
(a) 上記の式から、解状態の数を増やすと反復回数が減少することがわかります。分数がまだ小さい場合、がどのように減少するかを説明できます: 。
(b) 可能な解の空間()が増加すると、必要な反復回数は増加しますが、のようにしか増加しません。
ターゲットビット文字列のサイズを任意に長く増やすことができ、ターゲット状態の確率振幅が他の状態よりも少なくとも1桁大きいという結果が得られると仮定します。これは、グローバーのアルゴリズムを使用してターゲット状態を確実に見つけることができることを意味しますか?
答え:
いいえ。最初のアクティビティを20量子ビットで繰り返し、量子回路を数回num_shots = 10,000実行すると仮定します。一様確率分布は、すべての状態が1回でも測定される確率がであることを意味します。ターゲット状態を測定する確率が非解の10倍である場合(各非解の確率が対応してわずかに減少した場合)、ターゲット状態を1回でも測定する確率は約10%しかありません。ターゲット状態を複数回測定する可能性は非常に低く、ランダムに取得された多くの非解状態と区別できなくなります。良いニュースは、エラー抑制と緩和を使用することで、さらに高忠実度の結果を得ることができることです。
アクティビティ2: 正確なクエリアルゴリズムワークフロー
このアクティビティを最初のアクティビティとまったく同じように開始しますが、今度は別のQiskit愛好家とペアを組みます。秘密のビット文字列を選択し、パートナーは(一般的に)異なるビット文字列を選択します。それぞれがオラクルとして機能する量子回路を生成し、それらを交換します。次に、そのオラクルでグローバーのアルゴリズムを使用して、パートナーの秘密のビット文字列を決定します。
ステップ1: 古典的入力を量子問題にマッピングする
上記で定義したgrover_oracle関数を使用して、1つ以上のマークされた状態のオラクル回路を構築します。パートナーにマークした状態の数を伝えて、グローバー演算子を最適回数適用できるようにしてください。**ビット文字列を長くしすぎないでください。3-5ビットであれば、大きな困難なしに動作するはずです。**より長いビット文字列は、エラー緩和などのより高度な技術を必要とする深い回路をもたらします。
# Modify the marked states to mark those you wish to target.
marked_states = ["1000"]
oracle = grover_oracle(marked_states)
これで、ターゲット状態の位相を反転する量子回路を作成しました。以下の構文を使用して、この回路をmy_circuit.qpyとして保存できます。
from qiskit import qpy
# Save to a QPY file at a location where you can easily find it.
# You might want to specify a global address.
with open("C:\\Users\\...put your own address here...\\my_circuit.qpy", "wb") as f:
qpy.dump(oracle, f)
このファイルをパートナーに送信します(電子メール、メッセージングサービス、共有リポジトリなどを介して)。パートナーにも回路を送信してもらいます。簡単に見つけられる場所にファイルを保存してください。パートナーの回路を入手したら、それを視覚化できますが、それはクエリモデルを破ります。つまり、オラクルをクエリできる(オラクル回路を使用できる)が、どの状態をターゲットにしているかを判断するためにそれを検査できない状況をモデル化しています。
from qiskit import qpy
# Load the circuit from your partner's qpy file from the folder where you saved it.
with open("C:\\Users\\...file location here...\\my_circuit.qpy", "rb") as f:
circuits = qpy.load(f)
# qpy.load always returns a list of circuits
oracle_partner = circuits[0]
# You could visualize the circuit, but this would break the model of a query algorithm.
# oracle_partner.draw("mpl")
パートナーにエンコードしたターゲット状態の数を尋ね、以下に入力します。
# Update according to your partner's number of target states.
num_marked_states = 1
これは、次の式で最適なグローバー反復回数を決定するために使用されます。
grover_op = grover_operator(oracle_partner)
optimal_num_iterations = math.floor(
math.pi / (4 * math.asin(math.sqrt(num_marked_states / 2**grover_op.num_qubits)))
)
qc = QuantumCircuit(grover_op.num_qubits)
qc.h(range(grover_op.num_qubits))
qc.compose(grover_op.power(optimal_num_iterations), inplace=True)
qc.measure_all()
ステップ2: 量子ハードウェア実行のために問題を最適化する
これは以前とまったく同じように進みます。
# To run on hardware, select the backend with the fewest number of jobs in the queue
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
backend.name
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
circuit_partner_isa = pm.run(qc)
ステップ3: Qiskitプリミティブを使用して実行する
これも最初のアクティビティのプロセスと同じです。
# To run on a real quantum computer (this was tested on a Heron r2 processor and used
# 4 seconds of QPU time)
from qiskit_ibm_runtime import SamplerV2 as Sampler
sampler = Sampler(mode=backend)
sampler.options.default_shots = 10_000
result = sampler.run([circuit_partner_isa]).result()
dist = result[0].data.meas.get_counts()
ステップ4: 後処理と結果を目的の古典的形式で返す
サンプリング結果のヒストグラムを表示します。1つ以上の状態が他の状態よりもはるかに高い測定確率を持っているはずです。これらをパートナーに報告し、ターゲット状態を正しく決定したかどうかを確認します。デフォルトでは、表示されるヒストグラムは最初のアクティビティの同じ回路のものです。パートナーの回路から異なる結果が得られるはずです。
plot_distribution(dist)
理解度チェック
以下の質問またはプロンプトを読み、答えについて考えるか、パートナーとプロセスについて話し合ってください。ヒントや提案については、三角形をクリックしてください。
パートナーのターゲット状態を正しく取得しているはずです。そうでない場合は、パートナーと協力して何が問題だったのかを特定してください。以下をクリックしていくつかのアイデアを確認してください。
ヒント:
- パートナーの回路を視覚化/描画して、正しく読み込まれたことを確認してください。
- 使用した回路を比較し、期待される結果を得たものと比較してください。
- ビット文字列が長すぎないか、グローバー反復回数が禁止的に高くないかを確認するために、使用した回路の深さを確認してください。
まだ行っていない場合は、パートナーが送信したオラクル回路を描画してください。各ゲートの効果について話し合い、ターゲット状態が何であったかを論じることができるかどうかを確認してください。これは、複数のマークされた状態の場合よりも、単一のマークされた状態の場合の方がはるかに簡単です。
ヒント:
- オラクルの仕事は、ターゲット状態の符号を反転することであることを思い出してください。
- MCMTGateは、制御に関与するすべての量子ビットが状態にある場合にのみ、状態の符号を反転することを思い出してください。
- ターゲット状態が特定の量子ビットに既にを持っている場合、その量子ビットに対して何もする必要はありません。ターゲットが特定の量子ビットにを持っていて、MCMTGateに符号を反転させたい場合は、オラクルでその量子ビットに
Xゲートを適用する必要があります(そしてMCMTGateの後でXゲートを元に戻します)。
グローバー演算子の反復を1回少なくして実験を繰り返します。まだ正しい答えが得られますか?なぜですか、またはなぜですか?
ガイダンス:
おそらくそうでしょうが、エンコードされた解の数に依存する可能性があります。これは微妙な点を強調しています: グローバー反復の「最適な」数は、マークされた状態を測定する確率をできるだけ高くする数です。しかし、それよりも少ない反復でも、マークされた状態を他の状態よりもかなり可能性が高くすることができます。したがって、最適な数よりも少ない反復で済む可能性があります。これにより、回路の深さが減少し、したがってエラー率が減少します。
誰かがここで識別された「最適な数」よりも少ないグローバー反復を使用したいのはなぜですか?
答え:
グローバー反復の「最適な」数は、ノイズがない場合にマークされた状態を測定する確率をできるだけ高くする数です。しかし、それよりも少ない反復でも、マークされた状態を他の状態よりもかなり可能性が高くすることができます。したがって、最適な数よりも少ない反復で済む可能性があります。これにより、回路の深さが減少し、したがってエラー率が減少します。
アクティビティ3: グローバーのアルゴリズムでマインスイーパーのグリッドを解く
前のセクションで、グローバーのアルゴリズムは答えの知識からではなく、問題の制約からオラクルを構築できる場合に本当に有用になると述べました。マインスイーパーは完璧な例です: 番号のついたセルは隣接する地雷の数を示しており、それらの制約が地雷の位置を完全に決定します—しかし、設定を見つけるには検索が必要です。
マインスイーパーはNP完全であることが証明されています: 解くのは難しいですが、確認するのは簡単です。これにより、グローバーのアルゴリズムの自然な候補になります。もちろん、ノイズの多い量子コンピュータで完全な99グリッドを解くことはまだできません—回路が深すぎます。代わりに、将来のフォールトトレラントマシンで大きなボードにどのようにアプローチするかのおもちゃのデモンストレーションとして、小さなグリッドを使用します。
いくつかの重要な注意事項。グローバーのアルゴリズムは非構造化古典検索に対してのみ二次的な高速化を提供します。マインスイーパーには、賢い古典アルゴリズムが活用できる構造がほぼ確実にあります。また、指数関数的に増大する検索空間に対しては、の改善でも無限には対応できません。しかし、それらの懸念事項を脇に置いて、このおもちゃの問題を使って問題制約が量子オラクルにどのようにエンコードされるかを説明します。
グリッド
ここに私たちの小さなマインスイーパーグリッドがあります:

各空白セルは地雷が含まれているかどうかを示すバイナリ変数で表すことができます。これらを、、とラベル付けし、はそのセルに地雷があり、はないことを意味します:

約半秒で頭の中で解くことができますが、このおもちゃの問題を使って、より難しいボードに量子コンピュータでどのようにアプローチできるかを説明します。
制約のエンコード
各番号付きセルは隣接する空白セルに条件を課します。これらの条件を量子回路にエンコードできるブール式として表現する必要があります。
とに隣接する「1」セルは、それらのうちの1つだけに地雷が含まれていることを示します。これはまさに排他的論理和(XOR)演算であり、入力の1つだけが真の場合に真を返します:
同様に、もう一方の「1」セル(とに隣接)は次の条件を与えます:
「2」セルは3つの空白セルのうち2つに地雷が含まれなければならないと言います。XORはパリティ演算であるため、は変数が奇数個真の場合に真を返します。偶数個(具体的には2個)が真になることを求めるので、で否定します:
この式だけでは、状態の量子ビットがゼロまたは2個の場合に満たされます(パリティに関する命題であるため)。しかし、それぞれ少なくとも1つの地雷を必要とする他の2つの節と組み合わせると、満たす割り当ては正確に2つの地雷を持つものだけになります。
3つの条件はすべて同時に満たされなければならないので、論理積記号で結合します:
ステップ1: 古典的入力を量子問題にマッピングする
このブール式をオラクルとして機能する量子回路にエンコードする必要があります。XORの量子バージョンはCX(CNOT)ゲートで実現できます: 2つのCXゲートをデータ量子ビットからワークスペース(アンシラ)量子ビットに適用すると、それらのXORが効果的に計算され、結果がアンシラに格納されます。
3つのワークスペース量子ビットを導入します—各節に1つずつ。各ブール式の結果をその対応するワークスペース量子ビットに格納し、次に複数制御Zゲートを使用して3つのワークスペース量子ビットがすべてになる(3つの節がすべて同時に満たされる)3量子ビット状態の位相を反転します。
以下の最初のコードセルでは、オラクルの「計算」部分を構築します—各節を評価してワークスペース量子ビットに結果を書き込む部分です。
x = QuantumRegister(3, "x")
a = QuantumRegister(3, "a")
qc = QuantumCircuit(x, a)
# Clause 1: x0 XOR x1 -> stored in a[0]
qc.cx(x[0], a[0])
qc.cx(x[1], a[0])
# Clause 2: x1 XOR x2 -> stored in a[1]
qc.cx(x[1], a[1])
qc.cx(x[2], a[1])
# Clause 3: NOT(x0 XOR x1 XOR x2) -> stored in a[2]
qc.cx(x[0], a[2])
qc.cx(x[1], a[2])
qc.cx(x[2], a[2])
qc.x(a[2]) # The NOT
qc.draw("mpl", style="iqp")
この時点で、各節の結果はその対応するワークスペース量子ビットに格納されています。次に、3つのワークスペース量子ビットがすべてになる3量子ビットデータ状態がマイナス符号を獲得する必要があります。これを複数制御Zゲート(ターゲットにアダマールゲートを挟んだMCXゲートとして実装)で行います。
位相反転を適用した後、アンコンピュートする必要があります—逆順にすべての節評価ステップを元に戻し、ワークスペース量子ビットをにリセットします。これは、グローバー演算子の後続の反復のためにワークスペース量子ビットがクリーンであるために不可欠です。
# Multi-controlled Z: flip phase if all workspace qubits are |1>
qc.h(a[2])
qc.mcx([a[0], a[1]], a[2])
qc.h(a[2])
# Uncompute clause 3: NOT(x0 XOR x1 XOR x2)
qc.x(a[2])
qc.cx(x[2], a[2])
qc.cx(x[1], a[2])
qc.cx(x[0], a[2])
# Uncompute clause 2: x1 XOR x2
qc.cx(x[2], a[1])
qc.cx(x[1], a[1])
# Uncompute clause 1: x0 XOR x1
qc.cx(x[1], a[0])
qc.cx(x[0], a[0])
qc.draw("mpl", style="iqp")
この回路がオラクルです: マインスイーパーの3つの制約すべてを満たすデータ量子ビット状態の位相を反転し、ワークスペース量子ビットをに戻します。
次に、このオラクルから完全なグローバー演算子を構築します。reflection_qubits引数に注意してください: データ量子ビットxのみを渡します。ワークスペース量子ビットは検索空間の一部ではないためです。オラクルが適用されると、それらの仕事は完了します。
grover_op = grover_operator(qc, reflection_qubits=x)
grover_op.decompose(reps=0).draw(output="mpl", style="iqp")
3つのデータ量子ビットと1つの解状態で、最適なグローバー反復回数はなので、2回の反復を使用します。データ量子ビットにアダマールゲートを適用して初期重ね合わせを作成し、グローバー演算子を2回合成し、データ量子ビットのみを測定します。
x = QuantumRegister(3, "x")
a = QuantumRegister(4, "a")
meas = ClassicalRegister(3, "meas")
qc = QuantumCircuit(x, a, meas)
# Create superposition over the data qubits only
qc.h(x)
# Apply 2 iterations of the Grover operator
qc.compose(grover_op.power(2), inplace=True)
# Measure only the data qubits
qc.measure(x, meas)
qc.decompose().draw(output="mpl", style="iqp")
ステップ2: 量子ハードウェア実行のために問題を最適化する
以前と同様に、ターゲットバックエンドに対して回路をトランスパイルします。
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
print(backend.name)
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
circuit_isa = pm.run(qc)
次に、トランスパイルされた回路の深さを確認できます。マインスイーパーオラクルはワークスペース量子ビットと複数のCXゲートを使用するため、トランスパイルされた回路は前のアクティビティのものより深くなります。
print("The total depth is ", circuit_isa.depth())
print(
"The depth of two-qubit gates is ",
circuit_isa.depth(lambda instruction: instruction.operation.num_qubits == 2),
)
ステップ3: Qiskitプリミティブを使用して実行する
# To run on a real quantum computer (this was tested on a Heron r2 processor and
# used 4 sec. of QPU time)
from qiskit_ibm_runtime import SamplerV2 as Sampler
sampler = Sampler(mode=backend)
sampler.options.default_shots = 10_000
result = sampler.run([circuit_isa]).result()
dist = result[0].data.meas.get_counts()
# To run on local simulator:
# from qiskit.primitives import StatevectorSampler as Sampler
# sampler = Sampler()
# result = sampler.run([qc]).result()
# dist = result[0].data.meas.get_counts()
ステップ4: 後処理と結果を目的の古典的形式で返す
plot_distribution(dist)
101状態が他のどの状態よりもはるかに高い確率で現れるはずであり、地雷がとに位置していることを示します。量子コンピュータを使用して小さなマインスイーパーゲームを解きました!
もちろん、マインスイーパーの最良の古典アルゴリズムは、すべての可能な地雷配置を総当たり検索するよりも優れています—グリッドの構造を活用します。グローバーのアルゴリズムが利点を提供するのは、最大限に曖昧になるように設計された非常に難しいボードだけであり、それでも二次的な高速化は指数関数的な成長に無限には対応できません。しかし、真の要点はその技術です: 量子オラクルに問題制約をエンコードすることは、制約充足、組合せ最適化、その他多くの領域に拡張できる強力なパターンです。
質問と重要な概念:
重要な概念:
このモジュールでは、グローバーのアルゴリズムのいくつかの主要な機能を学びました:
- 古典的な構造化されていない検索アルゴリズムは、空間のサイズに対して線形にスケールするクエリ数を必要としますが、グローバーのアルゴリズムはのようにスケールするクエリ数を必要とします。
- グローバーのアルゴリズムは、一連の演算(一般的に「グローバー演算子」と呼ばれます)を何度も繰り返すことを含み、ターゲット状態を最適に測定される可能性が高くなるように選択された回数繰り返します。
- グローバーのアルゴリズムは、回未満の反復で実行でき、それでもターゲット状態を増幅できます。
- グローバーのアルゴリズムは計算のクエリモデルに適合し、ある人が検索を制御し、別の人がオラクルを制御/構築する場合に最も意味があります。また、他の量子計算のサブルーチンとして有用である可能性もあります。
- オラクルは、マインスイーパーの例で示されているように、解の知識からではなく問題の制約から構築できます。
T/F質問:
-
T/F グローバーのアルゴリズムは、構造化されていない検索で単一のマークされた状態を見つけるために必要なクエリ数で、古典的アルゴリズムに対する指数関数的な改善を提供します。
-
T/F グローバーのアルゴリズムは、解状態が測定される確率を反復的に増加させることによって機能します。
-
T/F グローバー演算子を反復するほど、解状態を測定する確率が高くなります。
MC質問:
- 文を完成させるための最良のオプションを選択してください。現代の量子コンピュータでグローバーのアルゴリズムを正常に使用するための最良の戦略は、グローバー演算子を反復することです...
- a. 1回のみ。
- b. 常に回、解状態の確率振幅を最大化するために。
- c. 回まで、ただし解状態を目立たせるにはそれより少なくても十分かもしれません。
- d. 10回以上。
- ここに示されている位相クエリ回路は、特定の状態を位相反転でマークするオラクルとして機能します。次のうち、この回路によってマークされる状態はどれですか?

- a.
- b.
- c.
- d.
- e.
- f.
- 128のセットから3つのマークされた状態を検索したいとします。マークされた状態の振幅を最大化するためのグローバー演算子の最適な反復回数は何ですか?
- a. 1
- b. 3
- c. 5
- d. 6
- e. 20
- f. 33
議論の質問:
-
グローバー検索として定式化できる他の問題は何ですか?解を見つけるのが難しいが、解を検証するのが簡単な問題を考えてください。
-
現代の量子コンピュータでグローバーのアルゴリズムをスケーリングすることに問題はありますか?